thank you for doing this .. but I am having a little trouble understanding video .. as there is little explanation.
If I have Google Scraper task setup .. how in n8n can load SCM Google Scraper task, update keywords, run the task, work with data IN N8N .. so i can save to DB , then loop to next set of keywords etc etc ???
That was the part I was having trouble with. the only way i could think of is wait for status to complete then import the CSV or Google Sheet file into n8n. It would be so much nicer if SCM could just return the array of data to n8n as a JSON so we could use it directly in n8n .. CSV imports can lead to issues etc.
all we need to do is return a JSON response back to n8n with the data in final task array, right? Unless SCM “forgets” each record when it saves to file.
I see you have 2 choices:
Add an array that accumulates task results as strings in RAM then return as JSON to n8n.
OR, upon task completion, load data from disk and put it in a JSON string to return to n8n.
n8n works extremely well with JSON formats. Not sure why you would want FTP at all.
I’m thinking you will probably go with #2 .. because then n8n doesn’t have to wait for task to complete while processing other nodes.
in n8n ..
Update Keywords
Run Task
Check Status
a. Loop over items → Check Task Status → Run other Nodes - Next Loop Item.
b. OR run n8n workflow on a timed schedule … either one can work in n8n
Upon Complete, Get task final result data
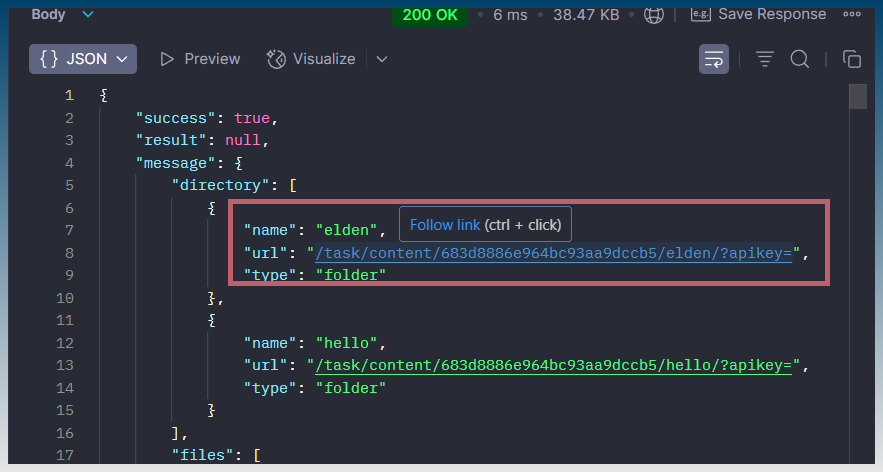
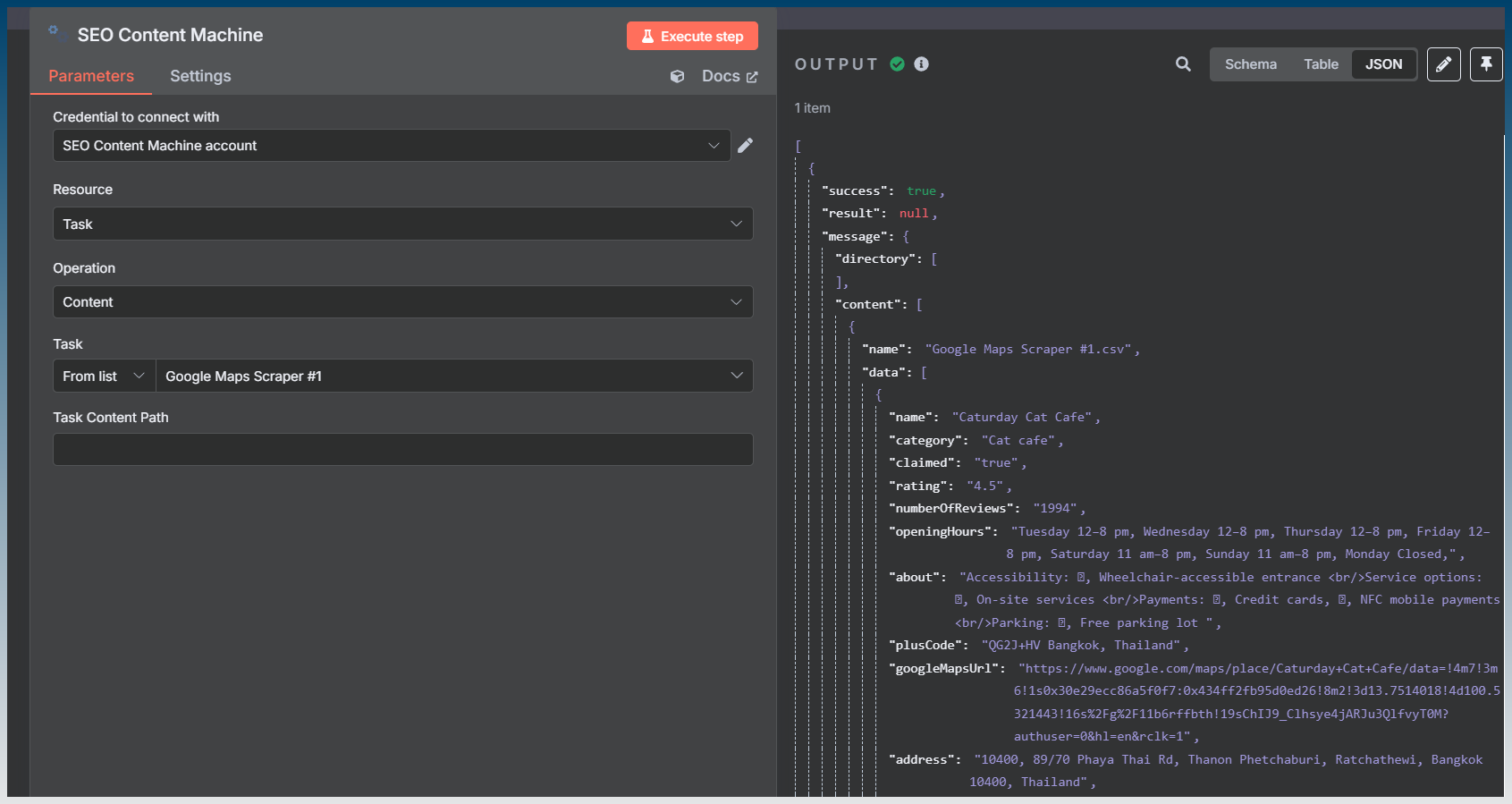
#4 is what I think you are creating now .. so it would have to be a file load from /content folder .. either CSV file for scaper .. or array of TXT/HTML files for other types for jobs.
Not sure how you set SCM up .. but here is the architecture I would recommend:
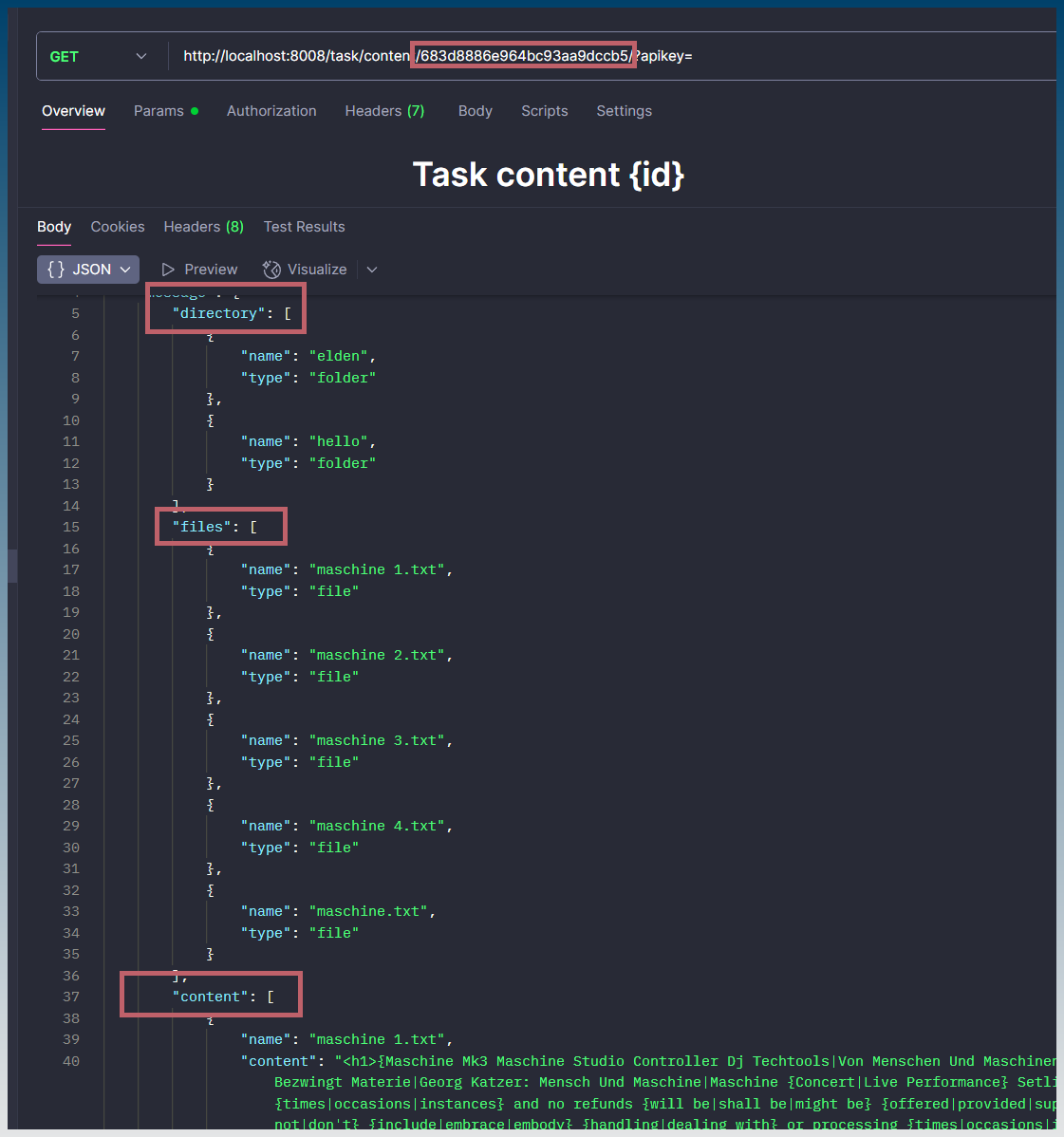
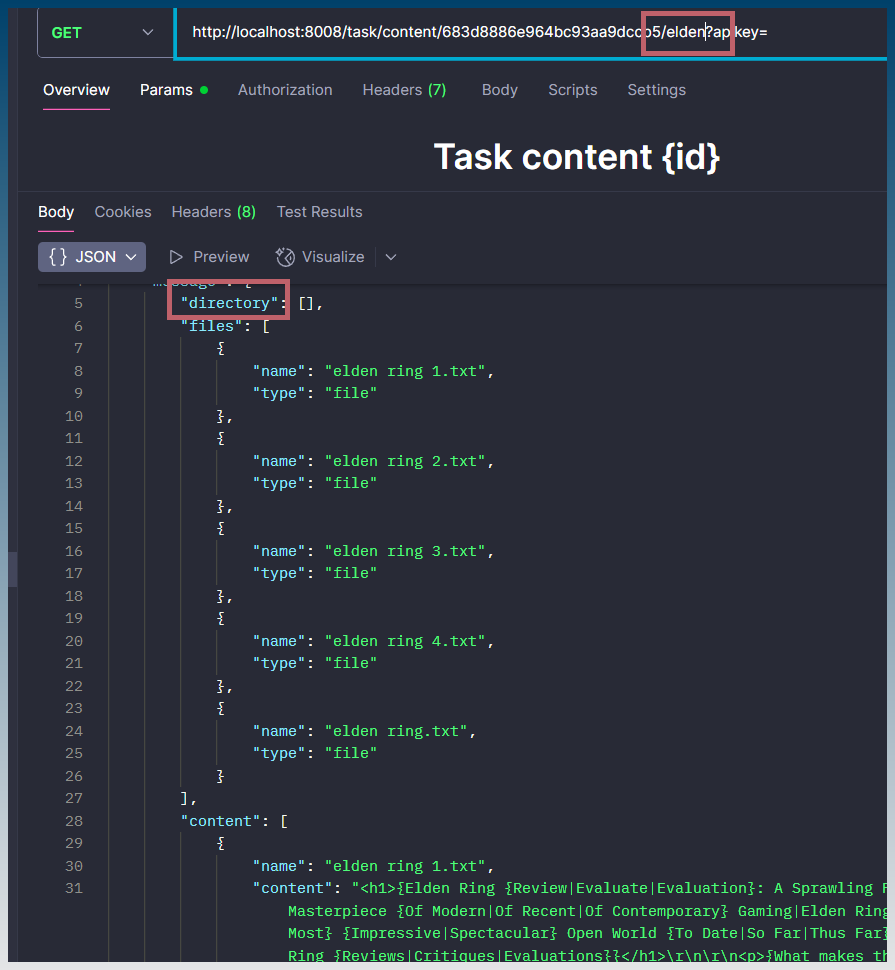
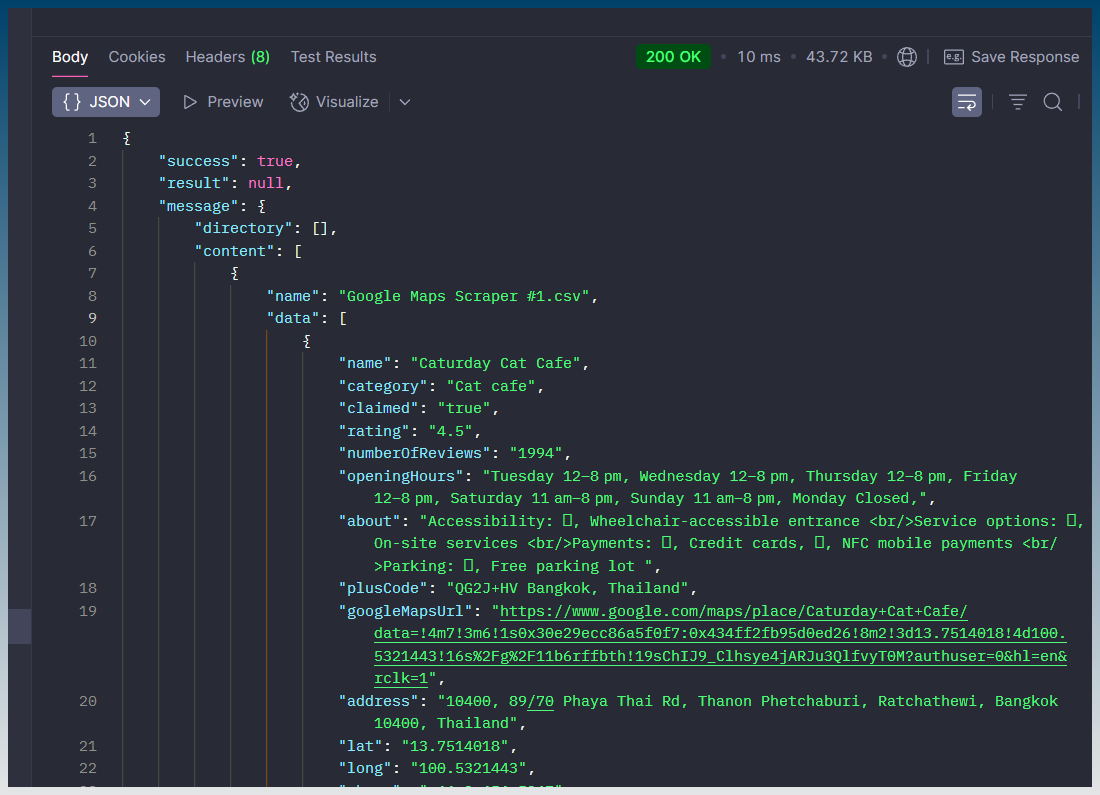
Add another API endpoint to SCM that retrieves a file and returns contents of a result file in a JSON based on TaskID + Keyword (+ ArticleID if applicable) … THEN .. if its a CSV (like scraper).. break it down to rows/fields in JSON so n8n can work directly with each data point.
In SCM n8n node .. let it query the new API Endpoint for each Keyword/ArticleID from the task record for JSON data.
This solution much cleaner and more reliable than using FTP.
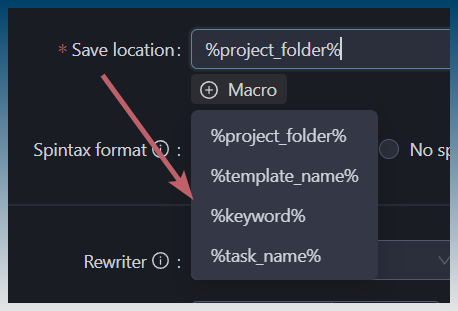
yes, I forgot you gave user full flexibility on naming convention.
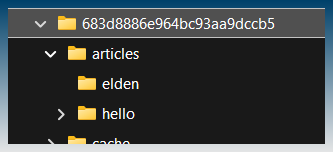
so you would have to refer to the naming convention the user has saved .. then pull the data based on that. You should pull actual file structure from filesystem to confirm and match it to the naming convention for reference.
Then you return JSON string .. based on similar folder structure. Although JSON might get large .. but n8n users should be aware to keep their tasks small and let n8n iterate through the bigger automation.
But also … if CSV (like scraper)… then break down rows, fields inside JSON as well. so that n8n can work with the data directly … users wont have to figure how to import/convert a huge CSV string.