1. Install LM Studio on your computer
Download and install LM Studio
2. Download model
Switch to power user UI
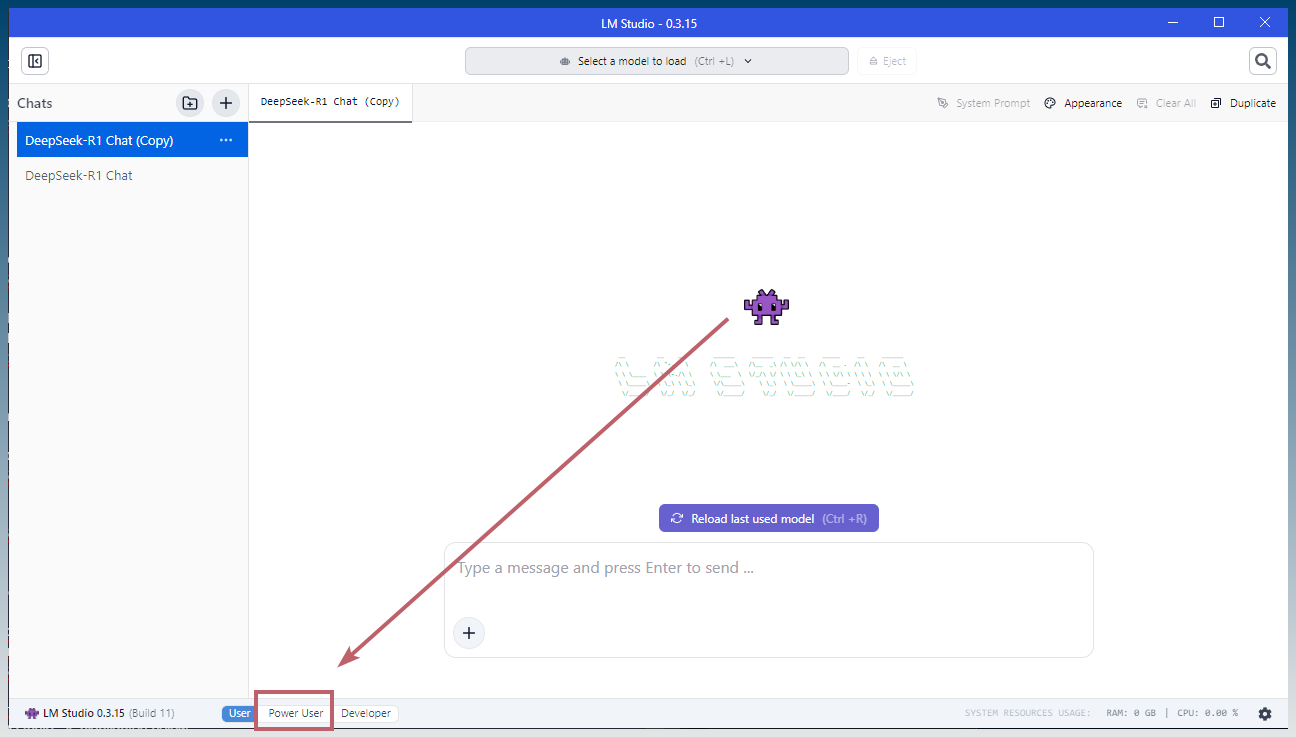
Click on discover
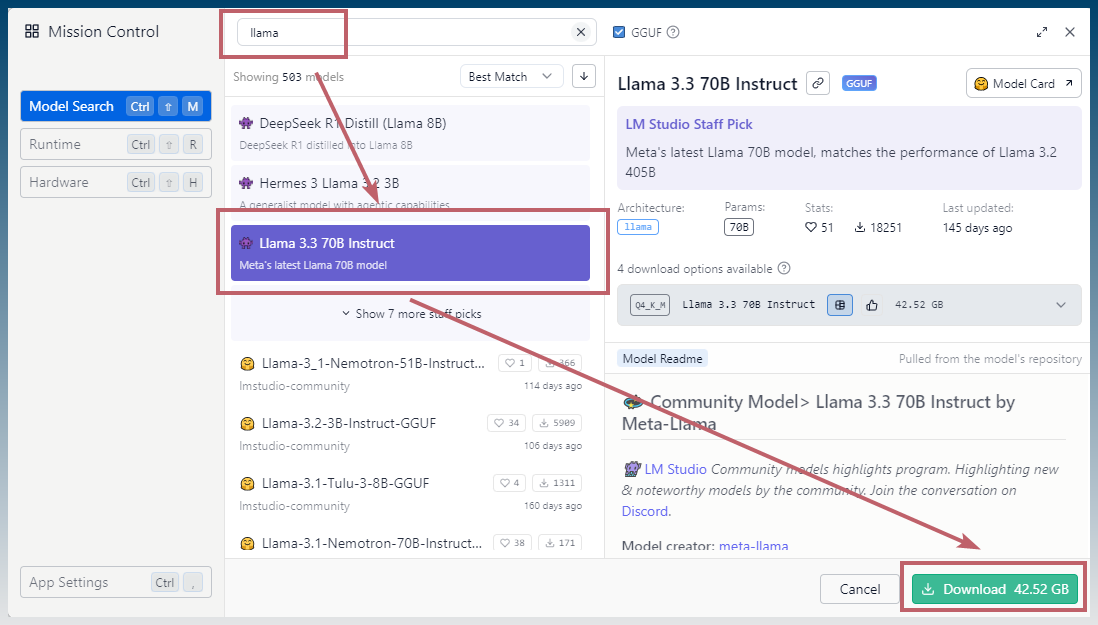
Find and install a model, eg Llama3, DeepSeek etc
If you are using a reasoning model that returns <think> tags, you should use DeepSeek inside SCM.
SCM will remove the think tag output for you automatically.
3. Load model
Click select a model
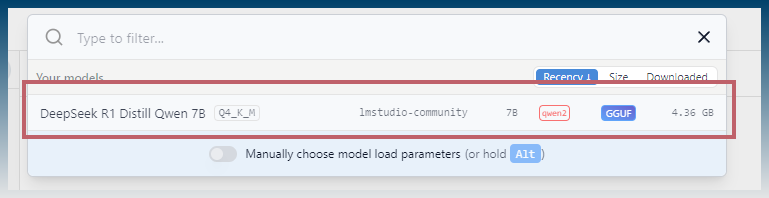
Click on model
Configure settings, eg allow GPU Offload to make it run quicker
Click load model
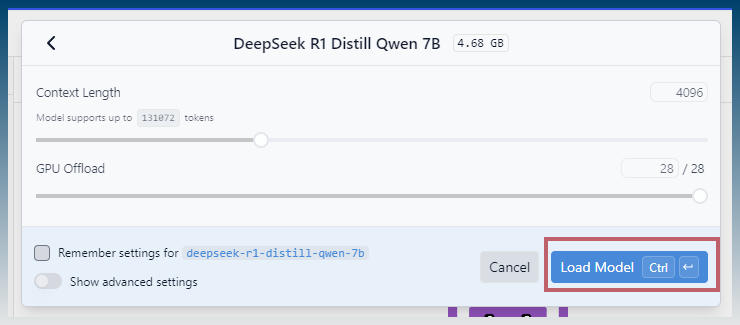
What model you can runs depends on your PC ram and graphics card.
Larger models require more ram.
Verify model is correctly loaded in UI
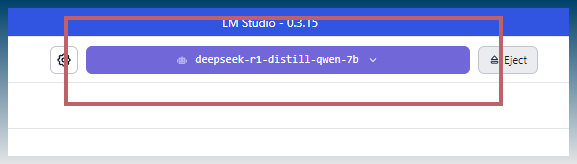
4. Start API server
We need to start the API server so SCM can access it.
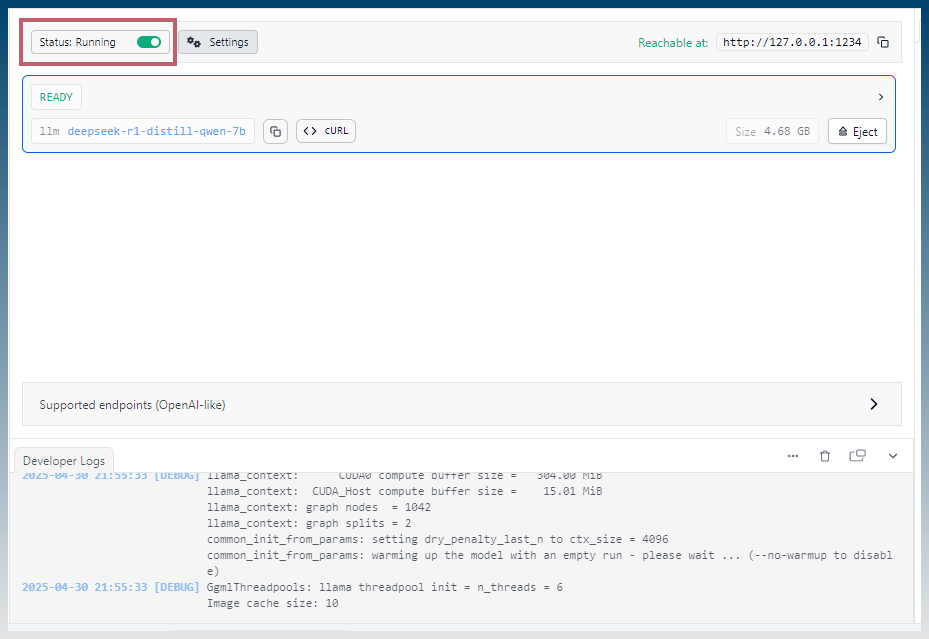
Click on developer

Make sure status says ‘Running’
Click on the toggle if it is not running.
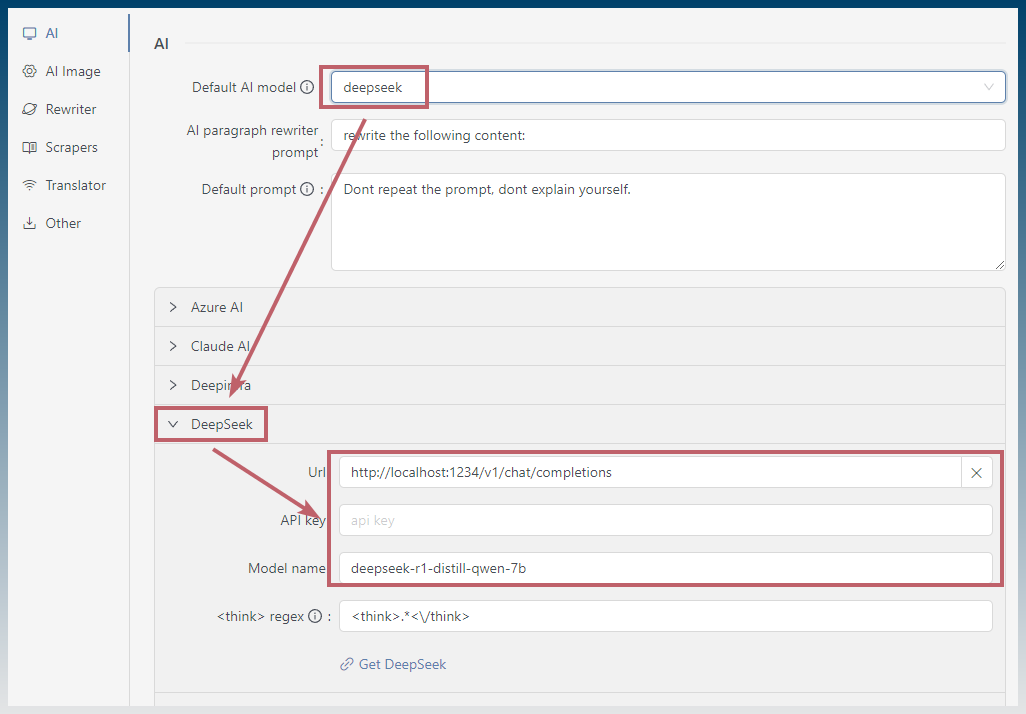
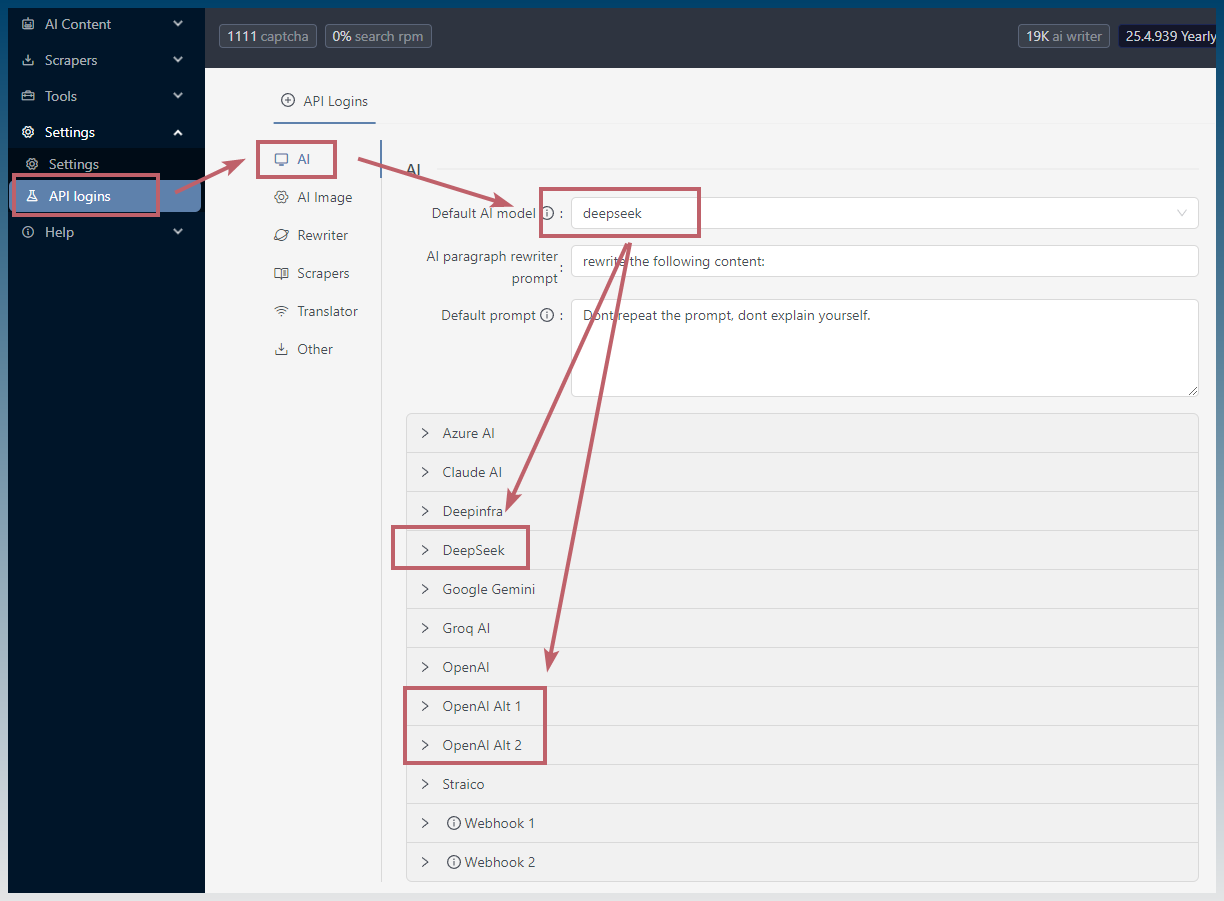
5. Fill out API details inside SCM
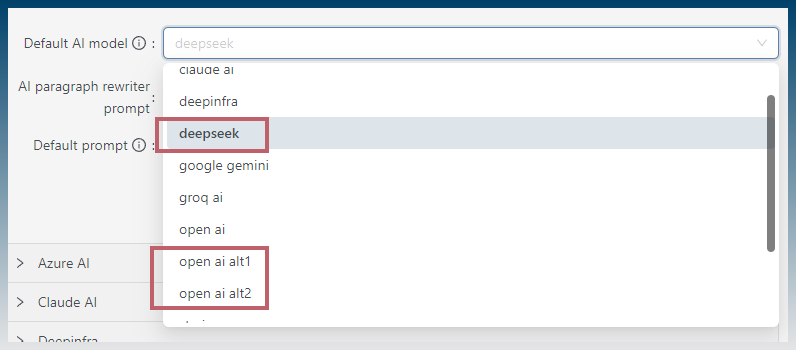
You must select either OpenAI Alt 1, 2 or DeepSeek (for reasoning models)
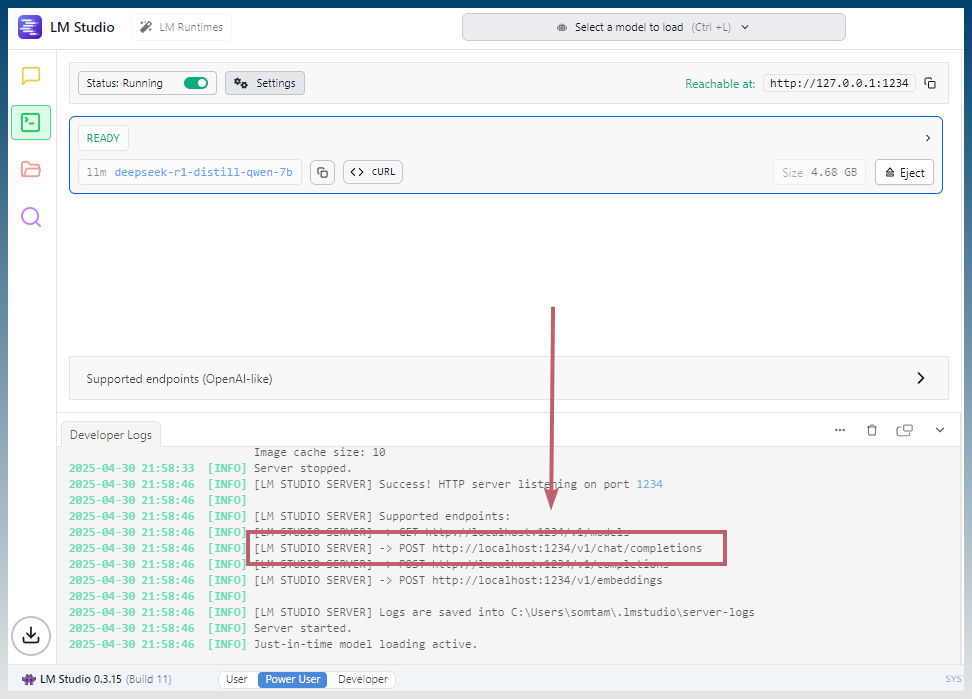
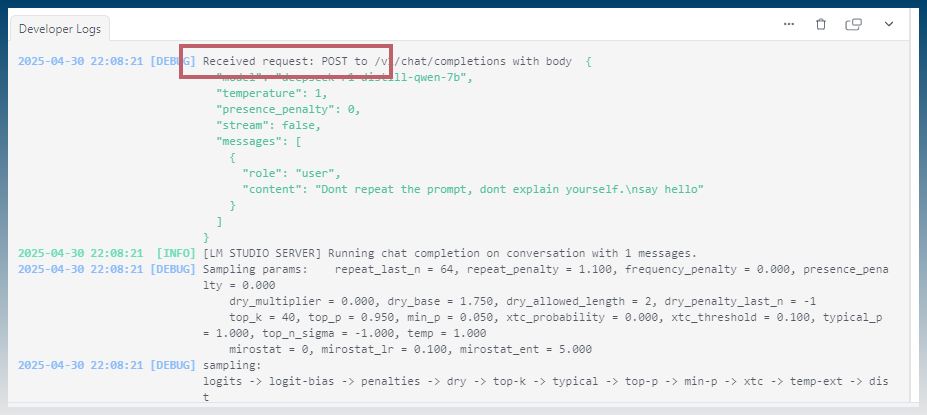
Find the completion URL of the model.
Check the developer logs for the full url.
You are looking for /chat/completions
eg: http://localhost:1234/v1/chat/completions
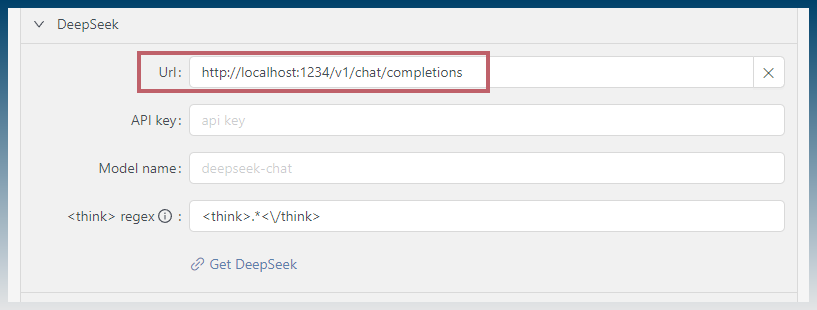
Copy and paste this into the URL field inside SCM.
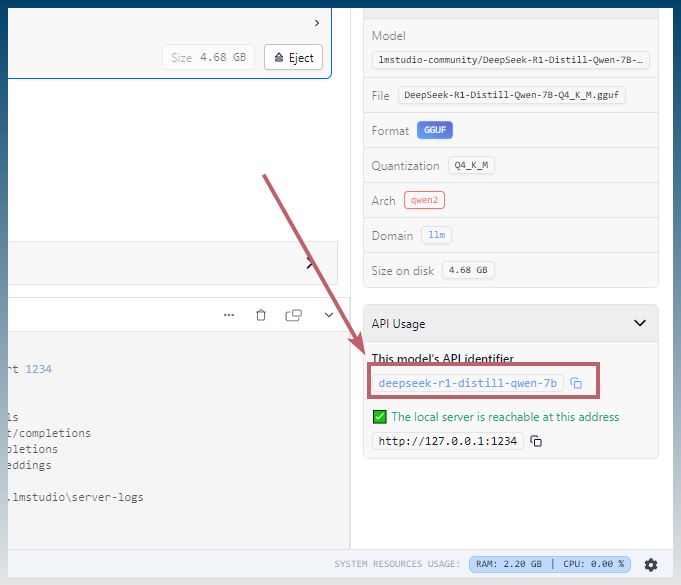
Find the model name in LM studio.
eg: deepseek-r1-distill-qwen-7b
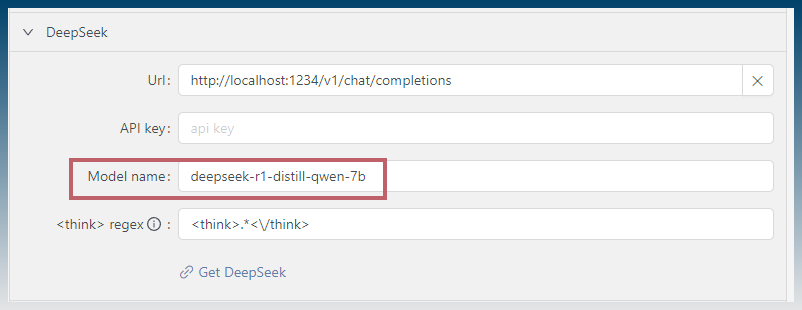
Copy and paste this into SCM.
6. Test
In SCM, select the correct AI service.
eg deepseek (or openAI alt)
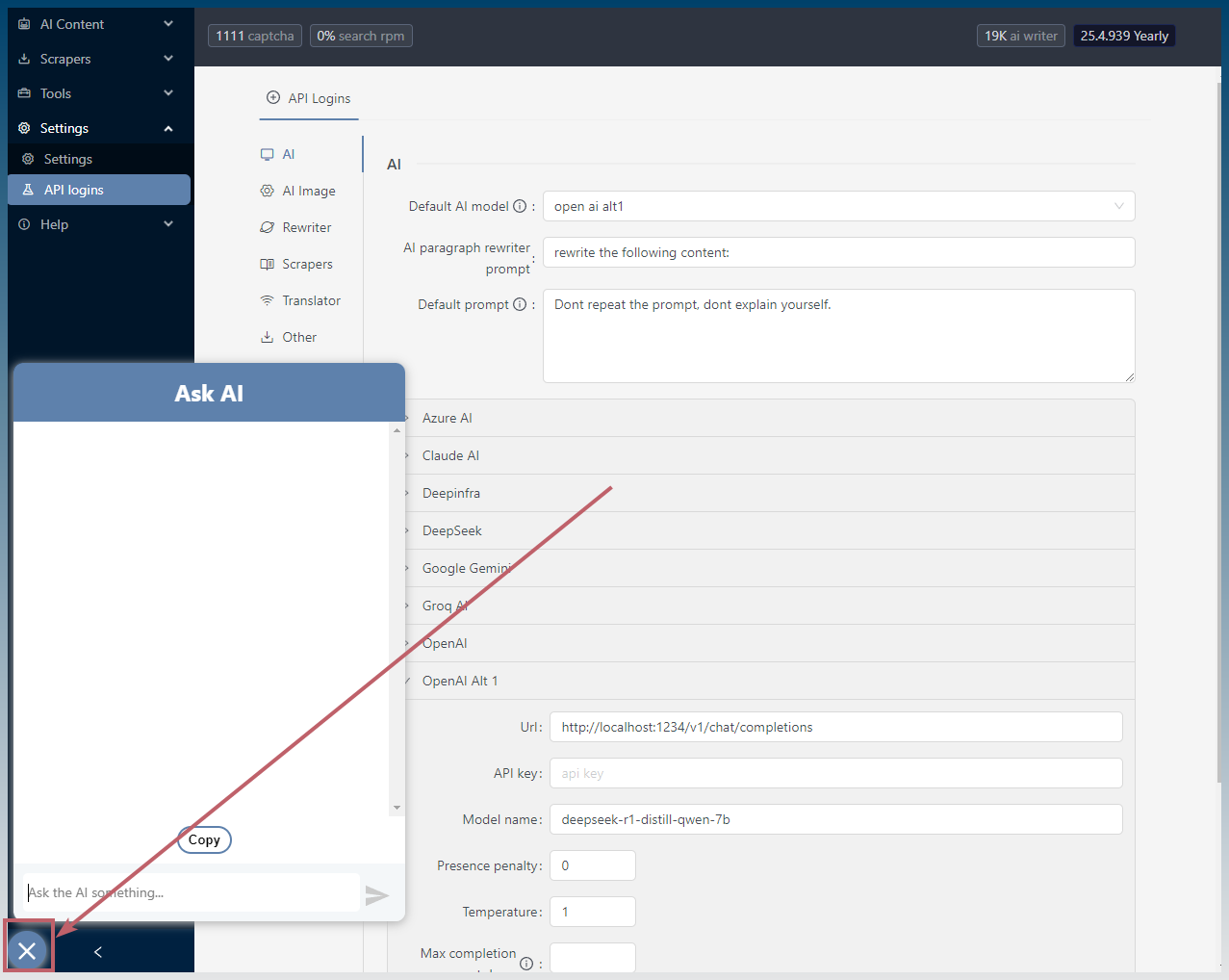
Open the Ask AI chat box
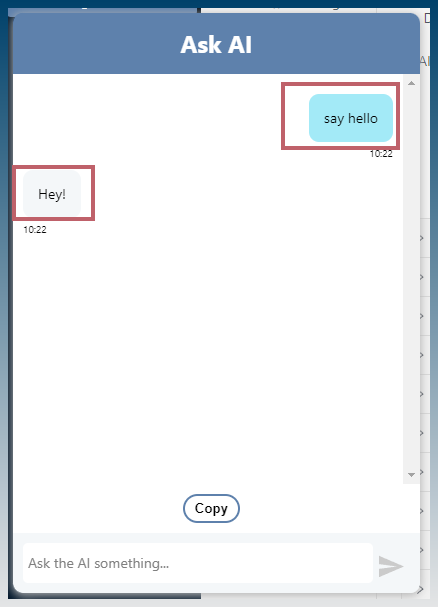
Say hello!
Check LM studio for errors.
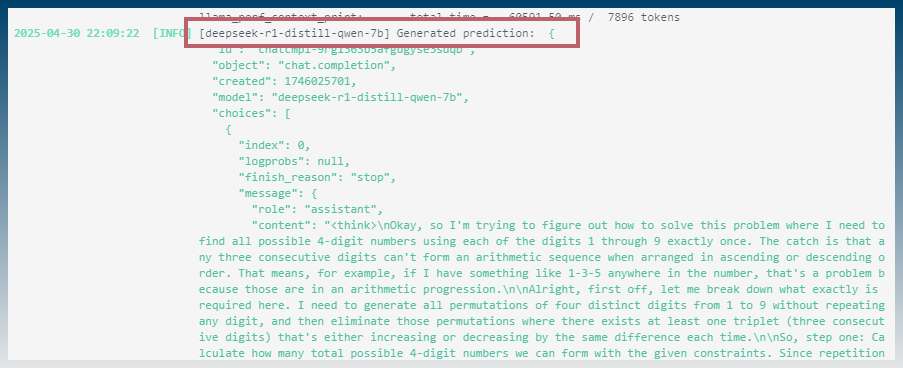
7. Troubleshooting errors
Chat returns error undefined retry…
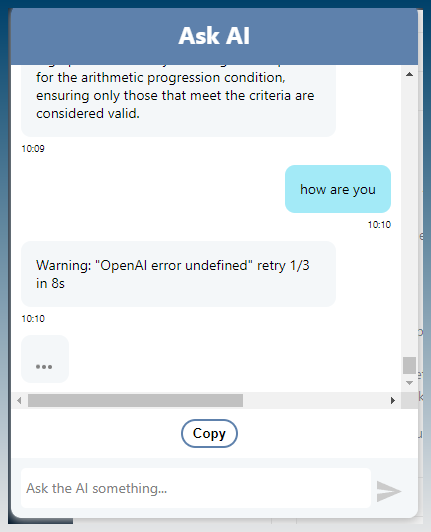
Check LM studio log.

Select correct endpoint (must end in /chat/completions)

Verify endpoint is pasted into SCM correctly.