Okay … when you watch the videos, it looks very complex, but here is how to make it easy for you to add ComfyUI to SCM via a simple API call.
BASIC STEPS NEEDED FOR COMFYUI API
- Load the Workflow JSON string in any programming language
- Change any desired field in the Workflow JSON string
- Wrap the whole definition into dict under the “prompt” key ({“prompt”: })
- Send it as POST request to http://127.0.0.1:8188/prompt (or any other url)
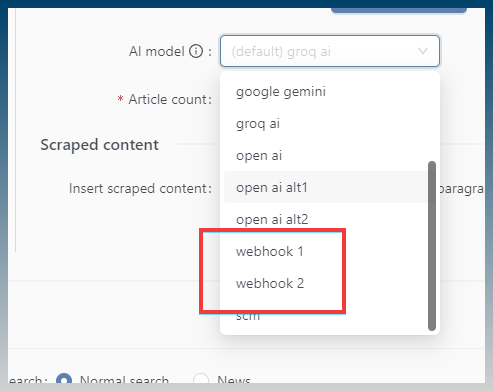
SO in SCM under Settings/API Logins … add a new API accordion tab, ask user for :
- ComfyUI Server Endpoint
- Workflow (as a textarea for JSON string)
- Image Prompt Tag (default it to “%IMGPROMPT%” or something that will jive nicely with the rest of SCM’s delimiters).
- Timeout (s).
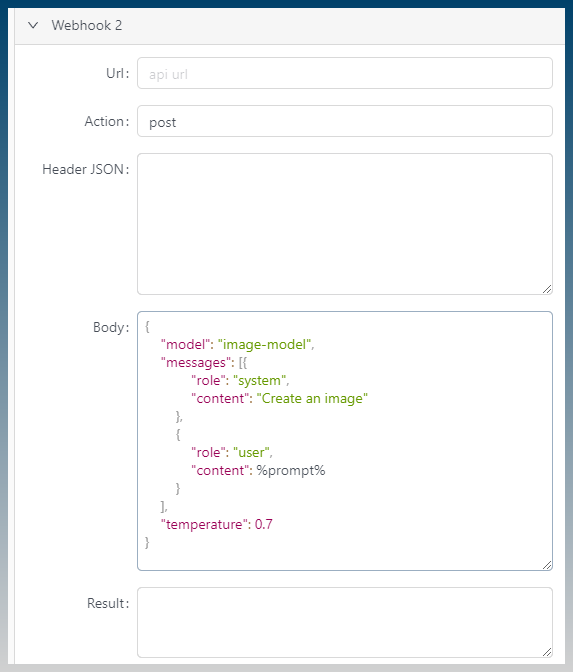
The Workflow is just a JSON string, and all SCM needs to do is replace the IMAGE PROMPT TAG with the value of the prompt from the SCM task.
The result will be a PNG image via API Websocket (or multiple images if a batch is run, but batches are not necessary for our purpose).
EXAMPLE:
When I saved the ComfyUI Workflow API json file, I got this code:
{
"5": {
"inputs": {
"width": 1024,
"height": 768,
"batch_size": 1
},
"class_type": "EmptyLatentImage",
"_meta": {
"title": "Empty Latent Image"
}
},
"6": {
"inputs": {
"text": "Realistic Photo of a massive tsunami about to hit the Statue of Liberty",
"clip": [
"11",
0
]
},
"class_type": "CLIPTextEncode",
"_meta": {
"title": "CLIP Text Encode (Prompt)"
}
},
"8": {
"inputs": {
"samples": [
"13",
0
],
"vae": [
"10",
0
]
},
"class_type": "VAEDecode",
"_meta": {
"title": "VAE Decode"
}
},
"10": {
"inputs": {
"vae_name": "flux-vae.safetensors"
},
"class_type": "VAELoader",
"_meta": {
"title": "Load VAE"
}
},
"11": {
"inputs": {
"clip_name1": "t5xxl_fp8_e4m3fn.safetensors",
"clip_name2": "clip_l.safetensors",
"type": "flux"
},
"class_type": "DualCLIPLoader",
"_meta": {
"title": "DualCLIPLoader"
}
},
"12": {
"inputs": {
"unet_name": "flux1-schnell-fp8.safetensors",
"weight_dtype": "fp8_e4m3fn"
},
"class_type": "UNETLoader",
"_meta": {
"title": "Load Diffusion Model"
}
},
"13": {
"inputs": {
"noise": [
"25",
0
],
"guider": [
"22",
0
],
"sampler": [
"16",
0
],
"sigmas": [
"17",
0
],
"latent_image": [
"5",
0
]
},
"class_type": "SamplerCustomAdvanced",
"_meta": {
"title": "SamplerCustomAdvanced"
}
},
"16": {
"inputs": {
"sampler_name": "uni_pc_bh2"
},
"class_type": "KSamplerSelect",
"_meta": {
"title": "KSamplerSelect"
}
},
"17": {
"inputs": {
"scheduler": "sgm_uniform",
"steps": 4,
"denoise": 1,
"model": [
"12",
0
]
},
"class_type": "BasicScheduler",
"_meta": {
"title": "BasicScheduler"
}
},
"22": {
"inputs": {
"model": [
"12",
0
],
"conditioning": [
"6",
0
]
},
"class_type": "BasicGuider",
"_meta": {
"title": "BasicGuider"
}
},
"25": {
"inputs": {
"noise_seed": 1028320977096301
},
"class_type": "RandomNoise",
"_meta": {
"title": "RandomNoise"
}
},
"26": {
"inputs": {
"images": [
"27",
1
]
},
"class_type": "PreviewImage",
"_meta": {
"title": "Preview Image"
}
},
"27": {
"inputs": {
"empty_cache": true,
"gc_collect": true,
"unload_all_models": true,
"image_pass": [
"8",
0
]
},
"class_type": "VRAM_Debug",
"_meta": {
"title": "VRAM Debug"
}
}
}
so all the user needs to do here is find his manual prompt in the API workflow he saved, and then change it to the Image Prompt Tag “%IMGPROMPT%”. Then copy/paste the whole JSON into SCM’s new API settings Workflow textarea box.
LIKE THIS:
{
"5": {
"inputs": {
"width": 1024,
"height": 768,
"batch_size": 1
},
"class_type": "EmptyLatentImage",
"_meta": {
"title": "Empty Latent Image"
}
},
"6": {
"inputs": {
"text": "%IMGPROMPT%",
"clip": [
"11",
0
]
},
"class_type": "CLIPTextEncode",
"_meta": {
"title": "CLIP Text Encode (Prompt)"
}
},
"8": {
"inputs": {
"samples": [
"13",
0
],
"vae": [
"10",
0
]
},
"class_type": "VAEDecode",
"_meta": {
"title": "VAE Decode"
}
},
"10": {
"inputs": {
"vae_name": "flux-vae.safetensors"
},
"class_type": "VAELoader",
"_meta": {
"title": "Load VAE"
}
},
"11": {
"inputs": {
"clip_name1": "t5xxl_fp8_e4m3fn.safetensors",
"clip_name2": "clip_l.safetensors",
"type": "flux"
},
"class_type": "DualCLIPLoader",
"_meta": {
"title": "DualCLIPLoader"
}
},
"12": {
"inputs": {
"unet_name": "flux1-schnell-fp8.safetensors",
"weight_dtype": "fp8_e4m3fn"
},
"class_type": "UNETLoader",
"_meta": {
"title": "Load Diffusion Model"
}
},
"13": {
"inputs": {
"noise": [
"25",
0
],
"guider": [
"22",
0
],
"sampler": [
"16",
0
],
"sigmas": [
"17",
0
],
"latent_image": [
"5",
0
]
},
"class_type": "SamplerCustomAdvanced",
"_meta": {
"title": "SamplerCustomAdvanced"
}
},
"16": {
"inputs": {
"sampler_name": "uni_pc_bh2"
},
"class_type": "KSamplerSelect",
"_meta": {
"title": "KSamplerSelect"
}
},
"17": {
"inputs": {
"scheduler": "sgm_uniform",
"steps": 4,
"denoise": 1,
"model": [
"12",
0
]
},
"class_type": "BasicScheduler",
"_meta": {
"title": "BasicScheduler"
}
},
"22": {
"inputs": {
"model": [
"12",
0
],
"conditioning": [
"6",
0
]
},
"class_type": "BasicGuider",
"_meta": {
"title": "BasicGuider"
}
},
"25": {
"inputs": {
"noise_seed": 1028320977096301
},
"class_type": "RandomNoise",
"_meta": {
"title": "RandomNoise"
}
},
"26": {
"inputs": {
"images": [
"27",
1
]
},
"class_type": "PreviewImage",
"_meta": {
"title": "Preview Image"
}
},
"27": {
"inputs": {
"empty_cache": true,
"gc_collect": true,
"unload_all_models": true,
"image_pass": [
"8",
0
]
},
"class_type": "VRAM_Debug",
"_meta": {
"title": "VRAM Debug"
}
}
}
Notice the only change was under block 6 where I swapped the manual prompt from my saved API workflow with %IMGPROMPT%.
Then all SCM needs to do is a simple replace of %IMGPROMPT% and post the entire JSON string as the final prompt to ComfyUI endpoint.
")