1. Create Dynamic Scraper
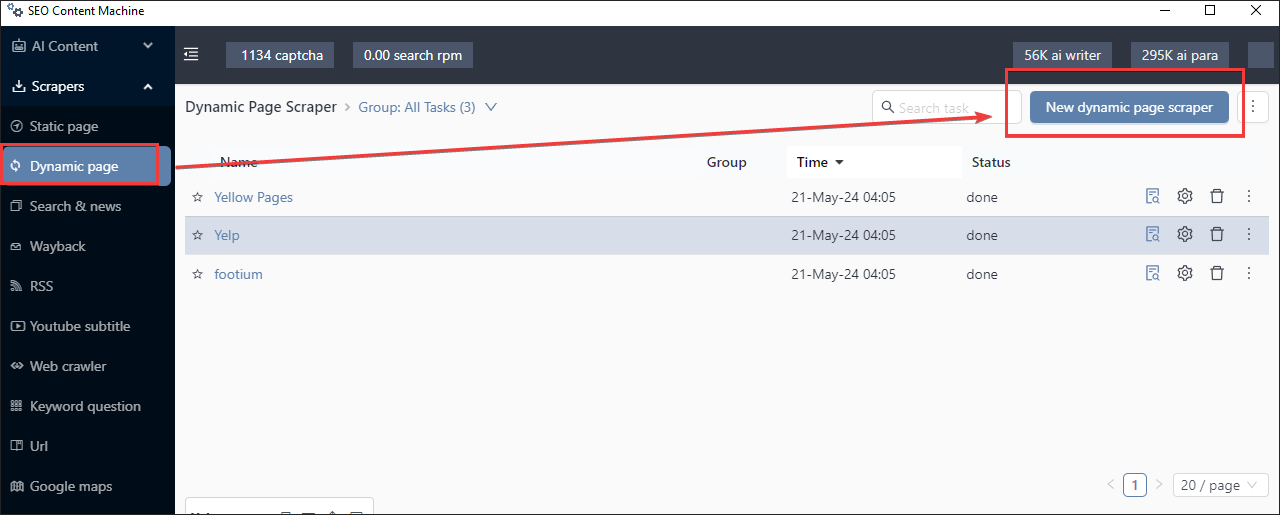
2. Load Yelp
Click picker
Hover over items you want to scrape
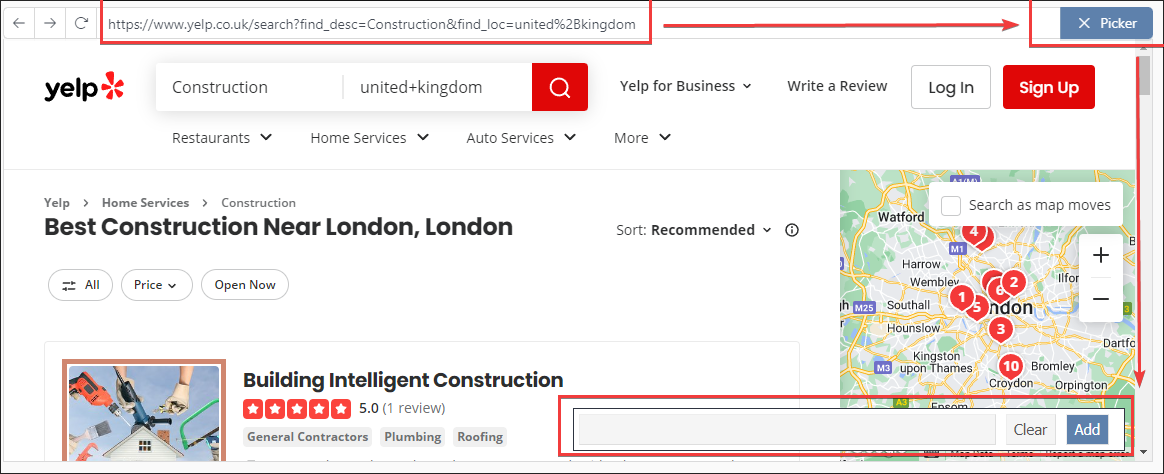
3. Find parent
Find the parent selector
Select the element that contains the elements we want to scrape
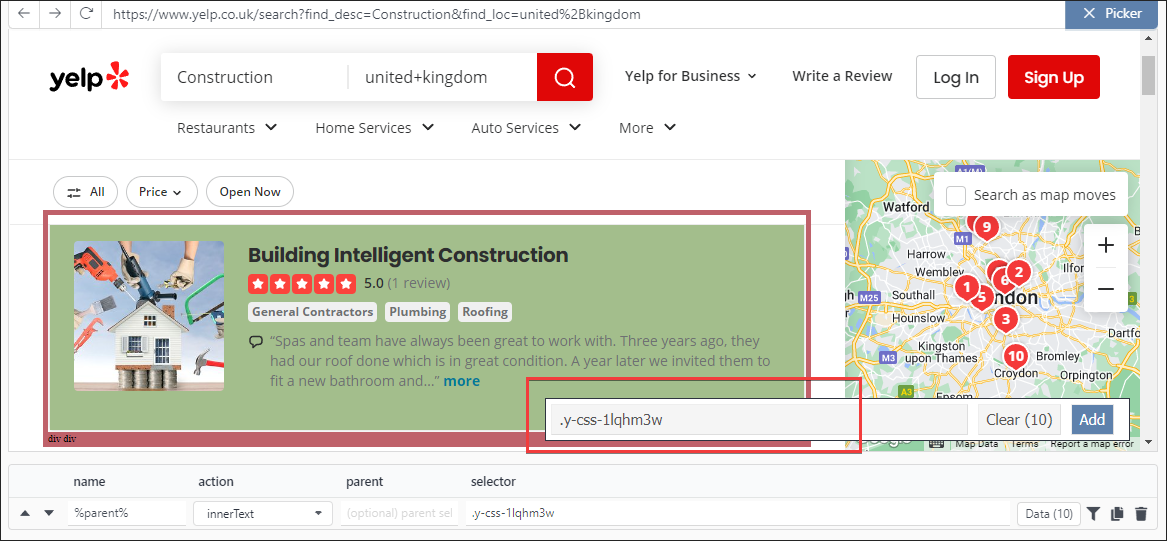
For yelp the parent class selector = .y-css-1lqhm3w
Visually we can see green box containing the details of one result
Notice also the count of items is 10, matching results per page
Add this selection as ‘%parent%’ so we can keep track of it
4. Add details
Capture the details of each result
Eg: Result name
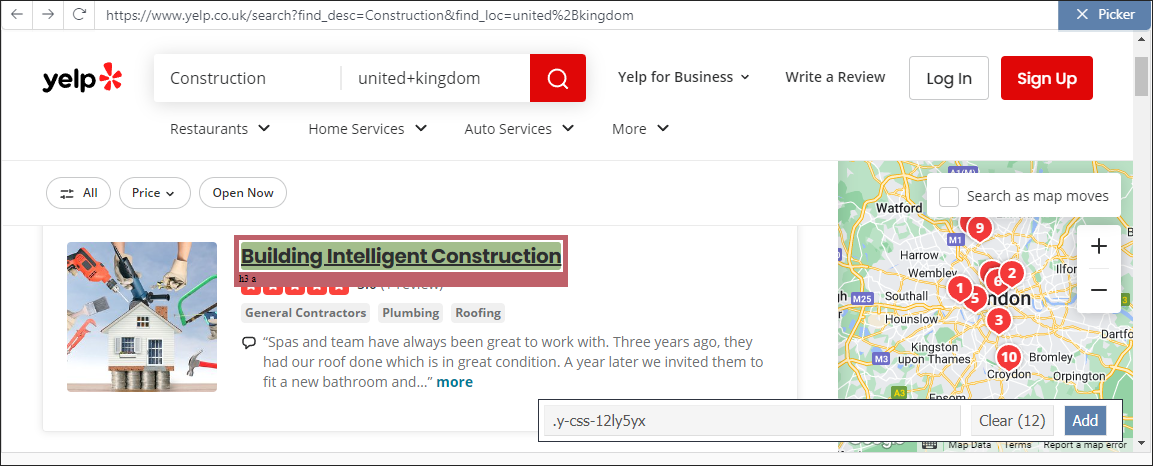
The class = .y-css-12ly5yx
Click Add

Data count is 12
It should be 10 per page
Copy and paste parent = .y-css-1lqhm3w

Data count is correct at 10
Click Data to verify content
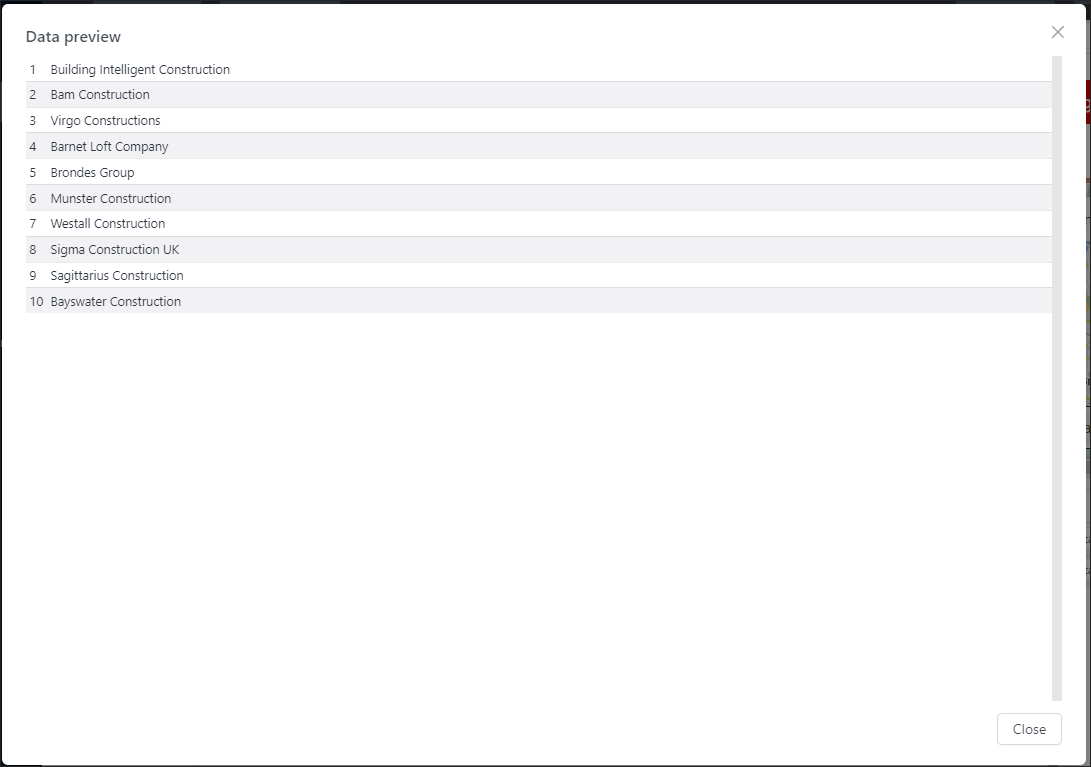
Name the item something meaningful eg %name%
Switch Export to CSV
You can see a preview of CSV table data
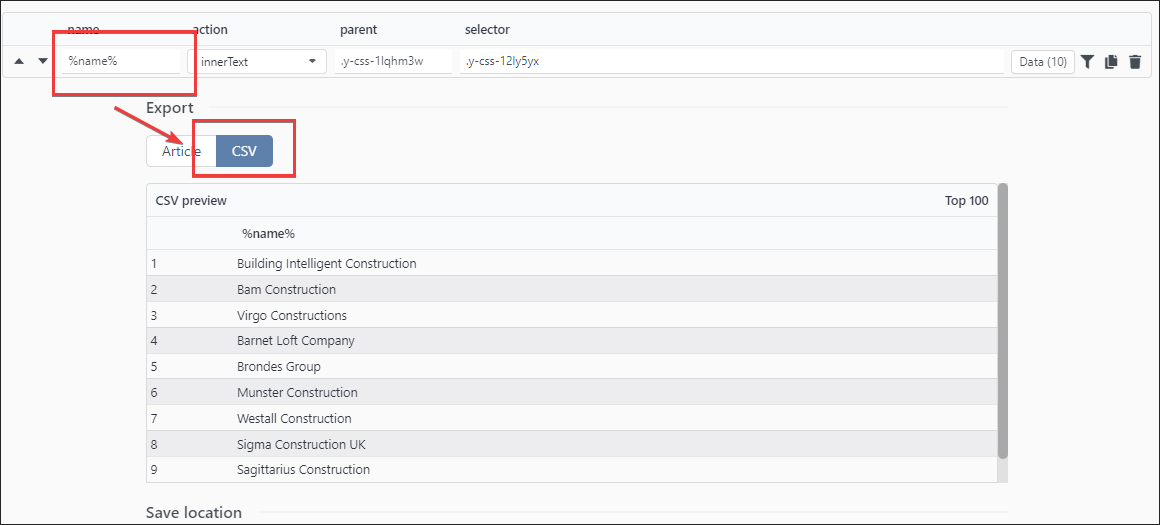
Repeat to find rest of items
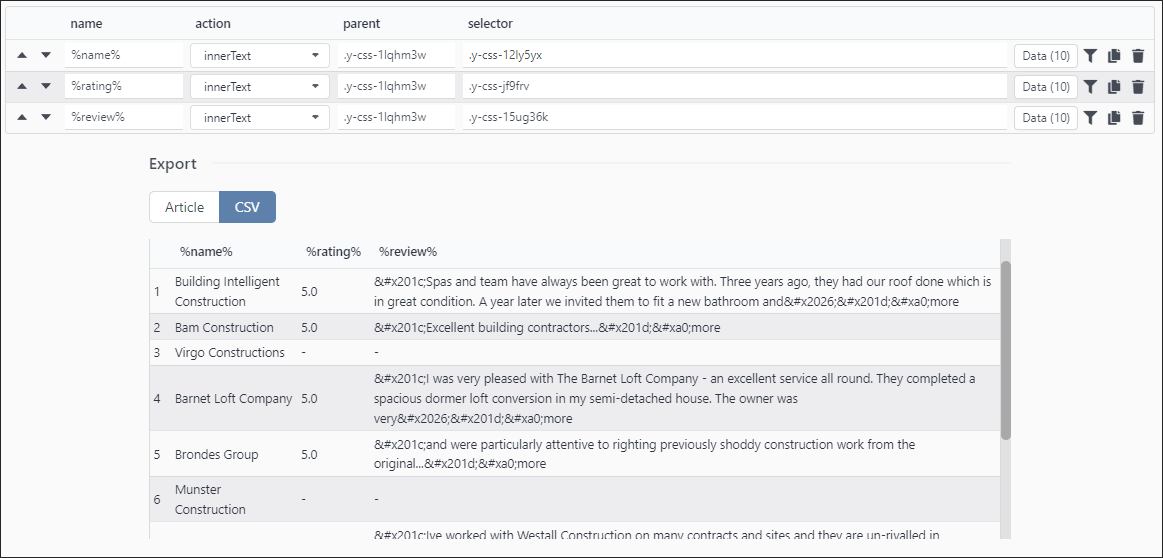
Why use parent selectors?
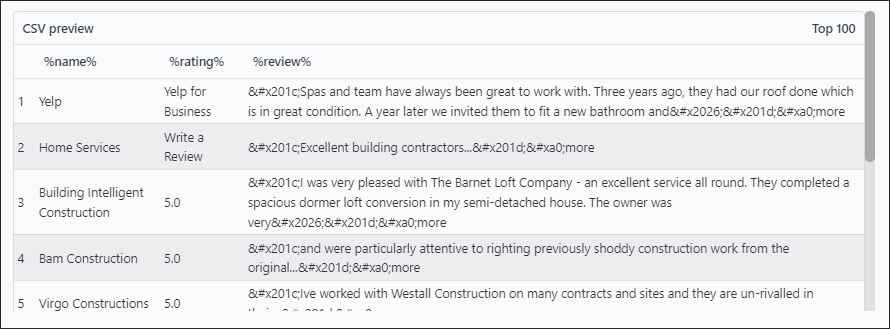
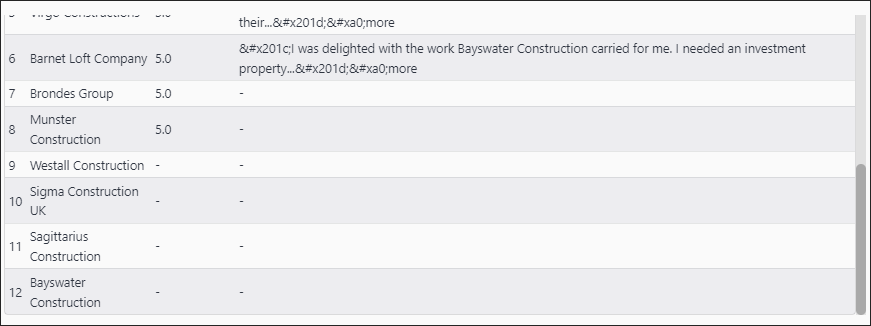
Notice how not all results have a rating
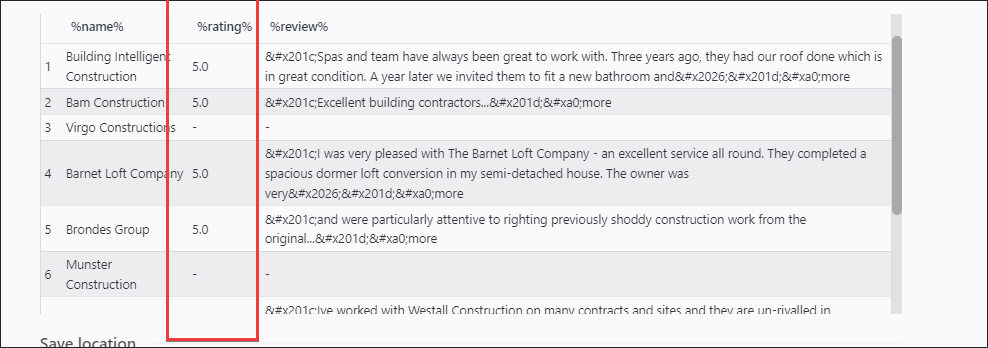
If we don’t use parent to contain results it looks like this
-
-
Selectors find extraneous data eg: ‘Yelp for Business’ in rating column
-
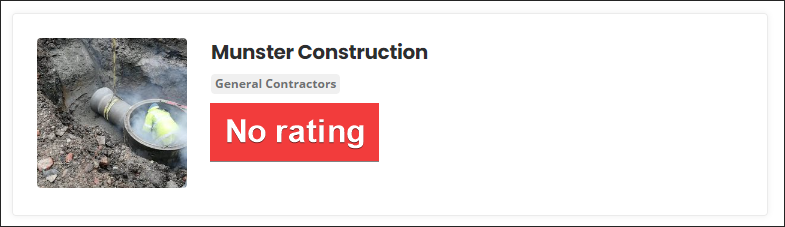
Unable to correctly match review score with proper result eg ‘Munster Construction’ has 5.0 rating, but in reality result has no rating.
Always find the parent element containing the data we want to scrape
This will even work for finding data in tables
The parent selector can be as simple as ‘table’
5. Paging results
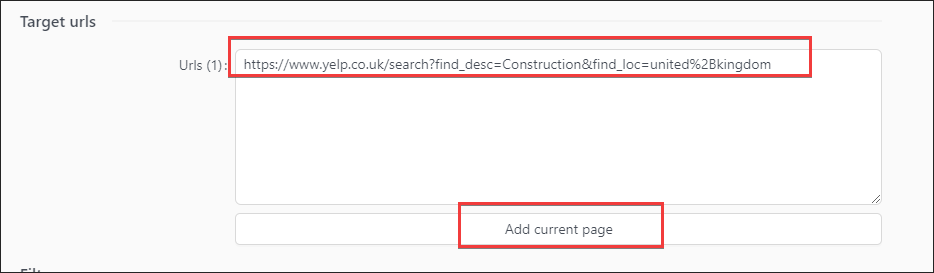
Click ‘Add current page’
Current yelp page is added to target list
Disable the picker
Now we can interact with the page
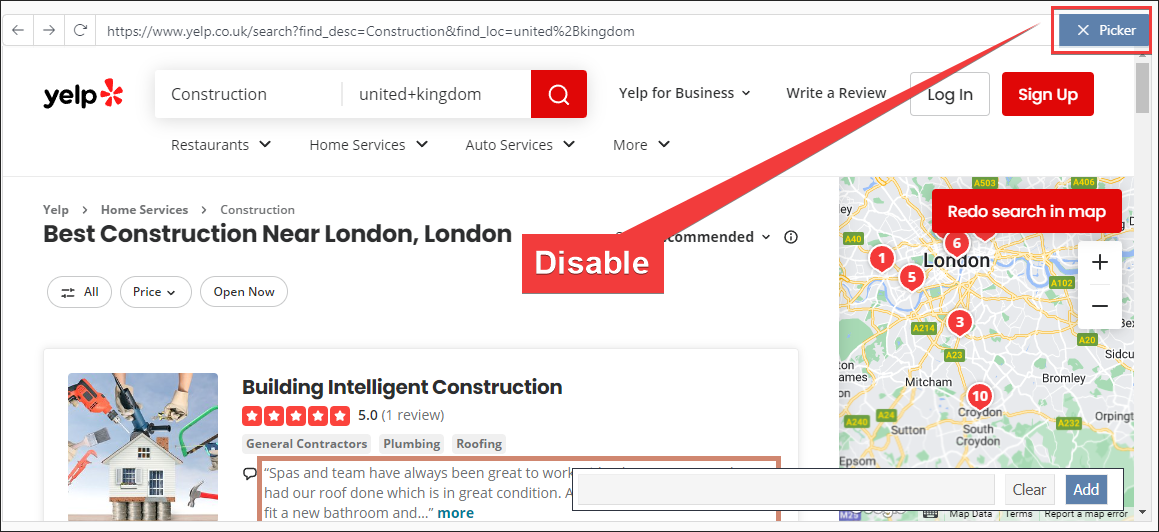
Scroll down to find the ‘Next’ page button
Click on it
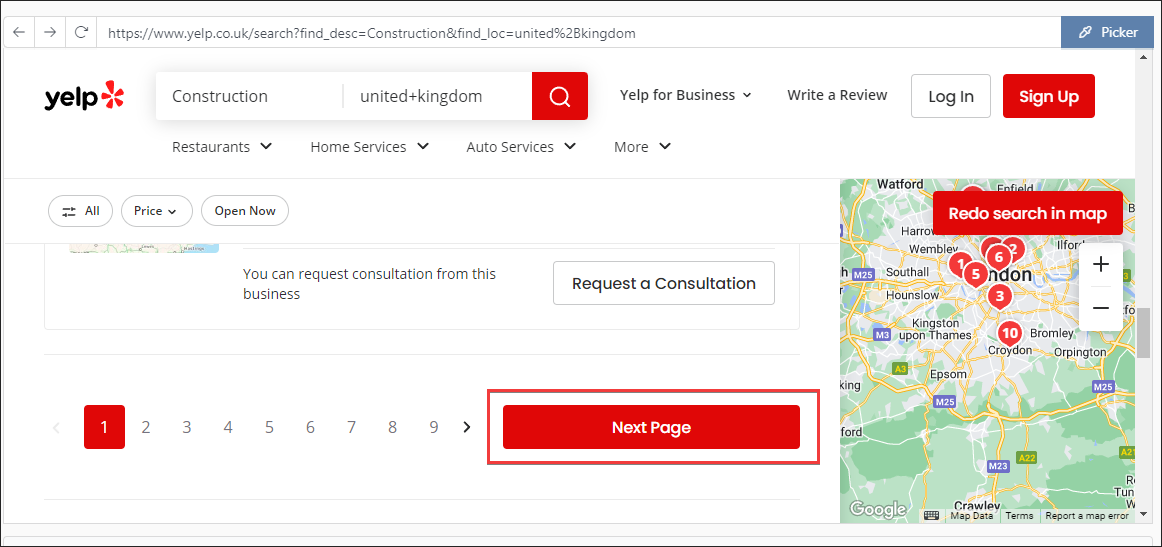
Notice the url bar changed
There is now a start=10 in the url
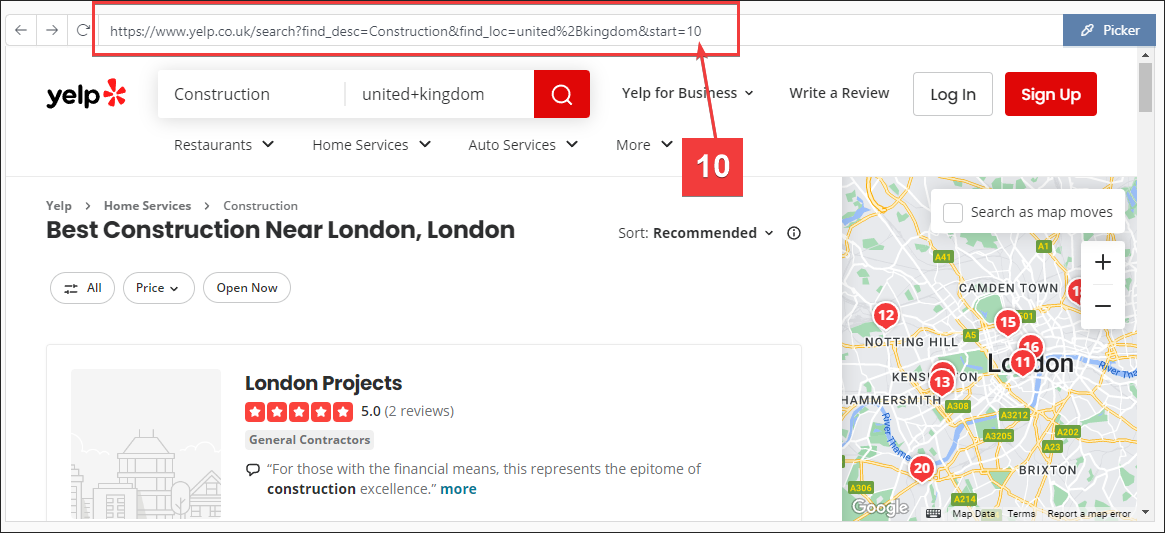
Click next page again
Notice its start=20
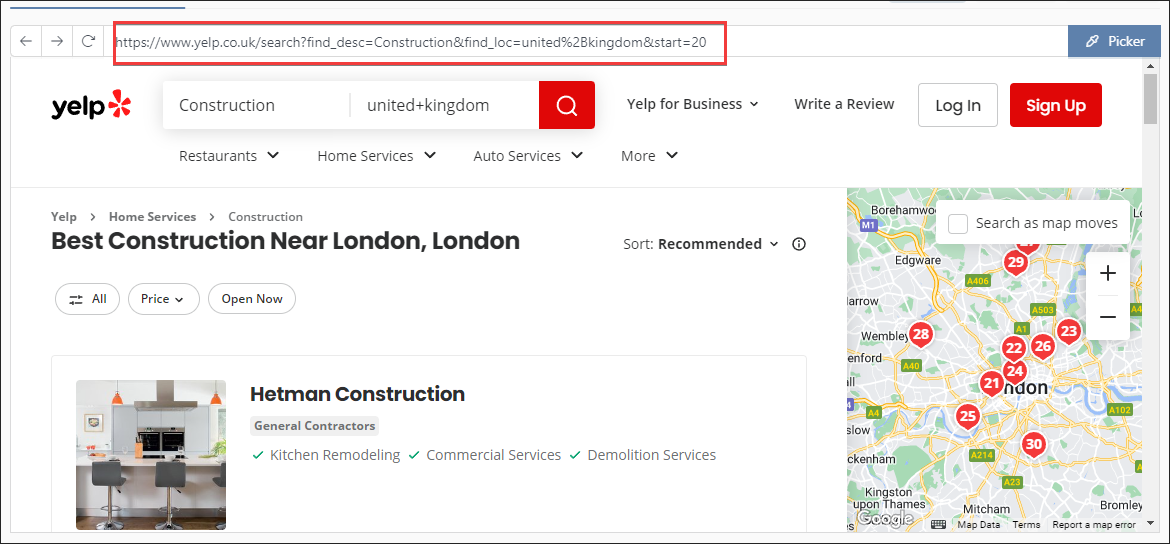
We can extrapolate to create list of urls with start=10,20,30,etc
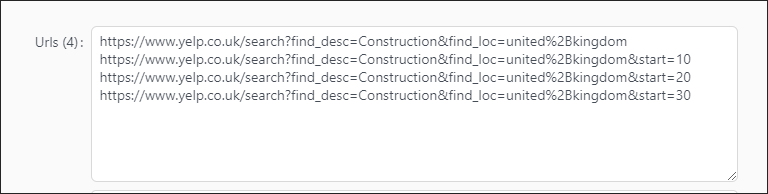
Sample
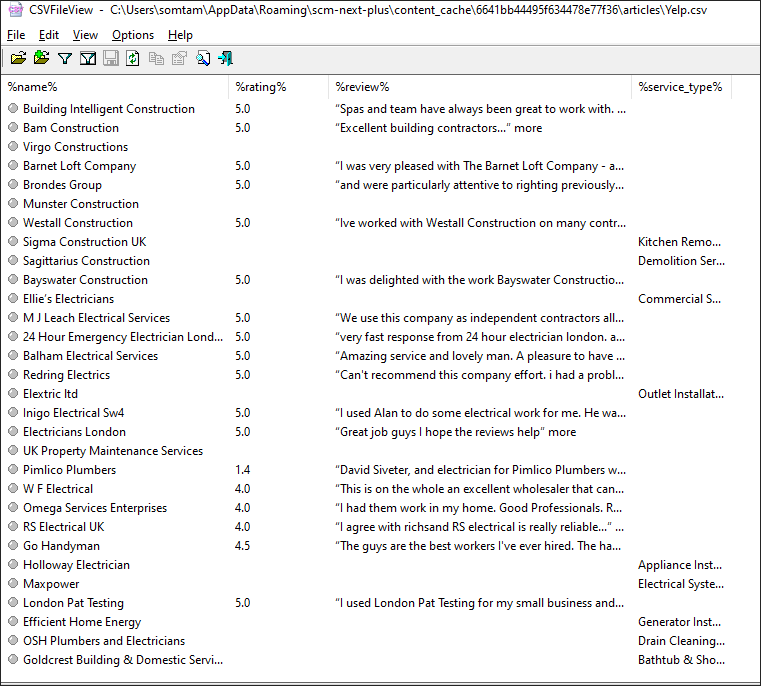
Project
Yelp.zip (1.4 KB)