The static scraper only allows scraping website content to individual TXT files or one large TXT file. However, to further process the scraped data, I want it in a CSV/Google Sheet with one row for each URL, like column A = URL and column B = scraped content. How can this be achieved?
The static scraper doesn’t have CSV or Google spreadsheet support right now.
You could do it using the Dynamic scraper instead
eg:
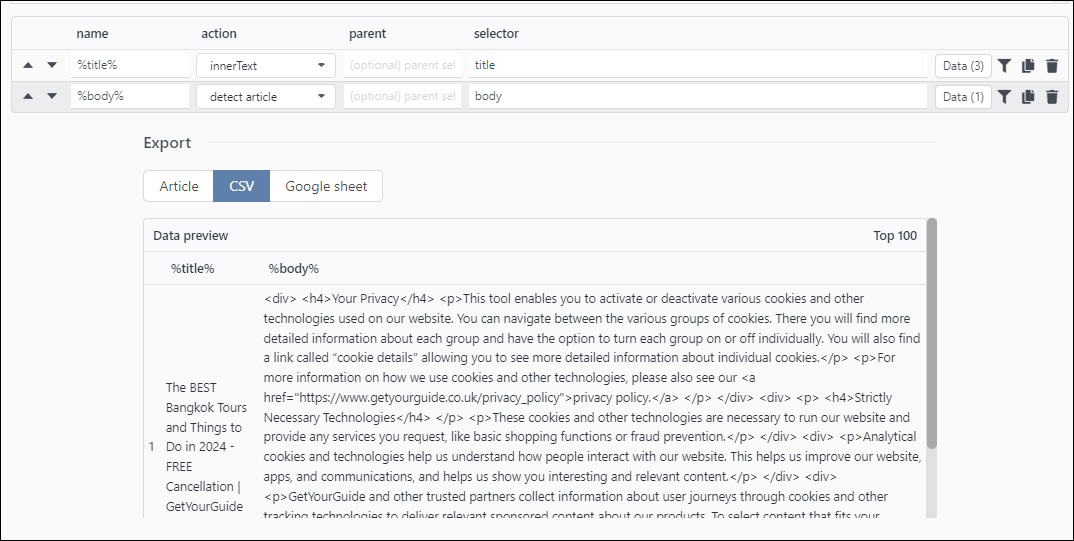
Selectors are:

Project sample
title body csv.zip (1.7 KB)
I did not think of that - thank you!
Let me know how it goes.
Also if the Google export works fine as well
Initial feedback:
-
I use innerText with body selector because “detect article” skips too much of the content I need. The result is a broken CSV unfortunately, I guess because of the quotes + commas + semicolons inside the scraped content which results in new rows. I’m currently testing this with Google Sheets output, but seeing that it first writes everything into a CSV as well instead of an XLSX or something, I assume I’ll run into the same issue. Edit: yes, same issue. While the Google export does work fine, I end up with way more rows than input URLs because depending on the scraped content it creates a new row.
-
I can’t figure out how to have the input URL in column A of the output file and the scraped content for that URL in column B. This is to be able to later merge the scraped data into existing sheets by matching the URLs within the existing sheets to parse the scraped content into the correct rows.
Can you export the project task for me?
I will have a closer look into it.
I’ve sent the export via DM.
P.S. Point 2 might be something you may have an answer to
@Tim Any update regarding the broken output?
I added some CSV escaping,
So all the text appears inside " " and any quotes etc are escaped as " in the text.
Re multilines, normally its a setting you might have to enable to allow line breaks inside csv cols.
AFAIK it should work fine in Google as it allows multiple lines in each cell.
Can you re run project with new update and let me know what has changed?
@Tim still no luck unfortunately - the CSV is still “broken” whether I open it locally with (I tried various settings) or import it into Google Sheets - same results just that some quotation marks are now escaped.
Can you give some screenshots of what error looks like?
Also you should export to google sheets directly and not via csv
@Tim I just DM’d you the CSV file that SCM created so you can analyze it. I’ll try direct Google Sheets export tomorrow and update you.
Error found in the CSV append to file code.
It was removing some lines causing the " formatting to break.
Its been fixed in newest update
Please test it
@Tim This did not fix the bug unfortunately. I just DM’d you the CSV that the SCM version with “fix: Dynamic scraper, csv output append to file corrupting output” created.
Edit: Sorry, it’s fixed! I didn’t delete the old CSV and re-running the project didn’t overwrite it. So what I was looking at was the data from the previous run with the previous SCM version…
Lovely all fixed right?
@Tim I was wrong about being wrong! ![]() It’s not fixed for my particular project at least. DM’d you the file.
It’s not fixed for my particular project at least. DM’d you the file.
I did a new update to change the " escape to " " , which on my testing worked better
@Tim Fix confirmed! Thank you!!! ![]()