Is there any way to reflect the value specified in some way if I can’t get the value in the Dynamic page?
For example, I would like to specify “empty”.
The reason is that after retrieving the page list, when I retrieve the values on the page individual pages with Dynamic page and insert the values by adding columns to the right of the original list list, if I cannot retrieve the values, the rows are skipped and it is difficult to add them to the appropriate rows in the original list.
For example, for a list of 65 individual pages, only 48 values could be retrieved.
Then, I cannot simply copy and paste the original 65 csv data.
Sounds complicated.
Can you put a screenshot or two with examples?

Ah I got you.
Right now its has to be done as 2 separate tasks.
As you correctly pointed out, the output is saved to the same sheet, and the rows don’t match.
So what you want is a task to
- scrape a list of urls
- use those urls as targets in dynamic scraper to scrape some content
But instead of doing it in 2 tasks, which require manual copying of output from first task… some how have it auto inject it as url results into another task and run it.
If it is possible to give some values to the rows that do not get values at 2, the data from 2 can be easily integrated into the csv data from 1 by copying and pasting.
Is there a way to automatically insert it into another task?
For example, does it mean that I can insert a value of 2 in column D if it matches the URL in column C?
The process I explained above is what you want to do right?
1st task to scrape urls
2nd task uses scrape urls as targets and does some other scraping
Currently there is no way to insert output of task 1 into task 2, has to be copy paste.
When I say insert I mean you want urls to be here:
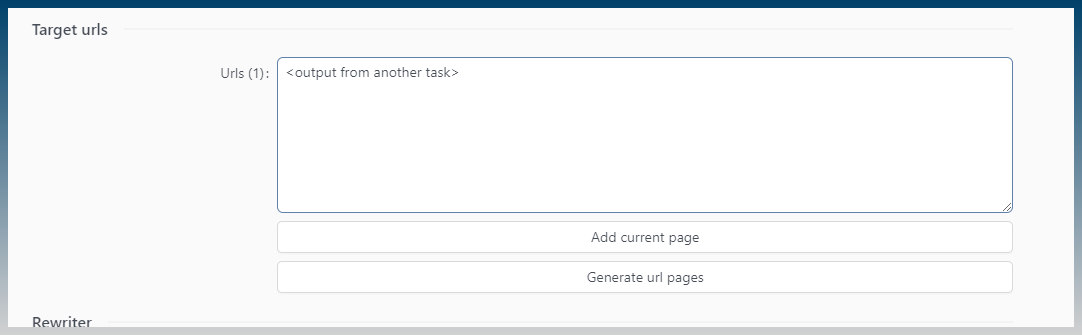
Not sure if it helps BUT
You can see that in the newest versions of dynamic scraper, if you insert the current page url, it does correctly fill down all the rows.
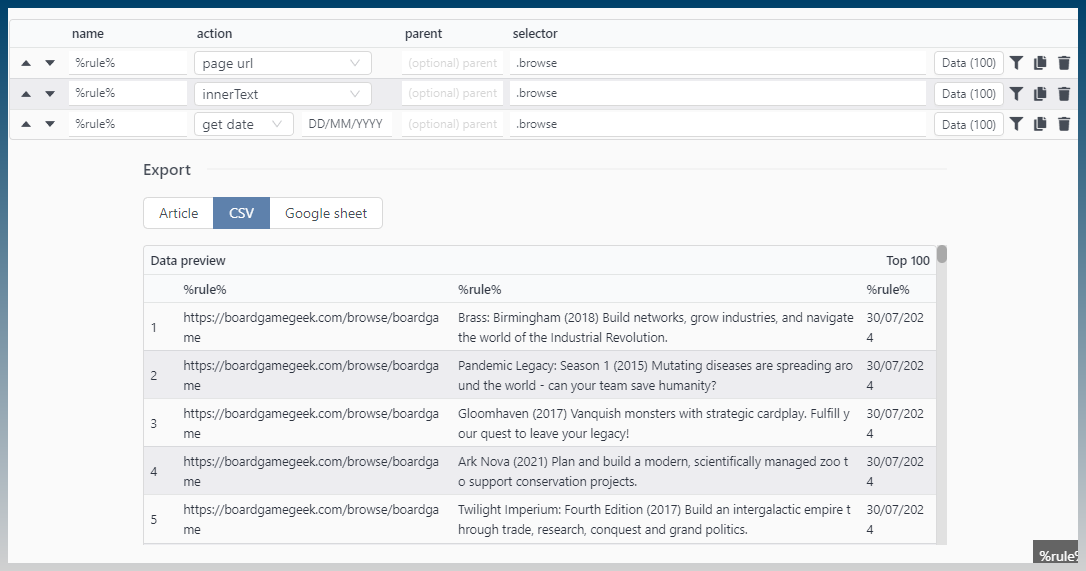
So this would be the site urls → xxx number of scraped rows from that page and you get the matching.
I will work on it and get back to you.
Thank you!
If you figure it out let me know,
I think you might require a feature that runs task 1 => copies output of task 1 into task 2 urls list.
Can you check the task because a duplicate line has occurred?
I will send you a message.