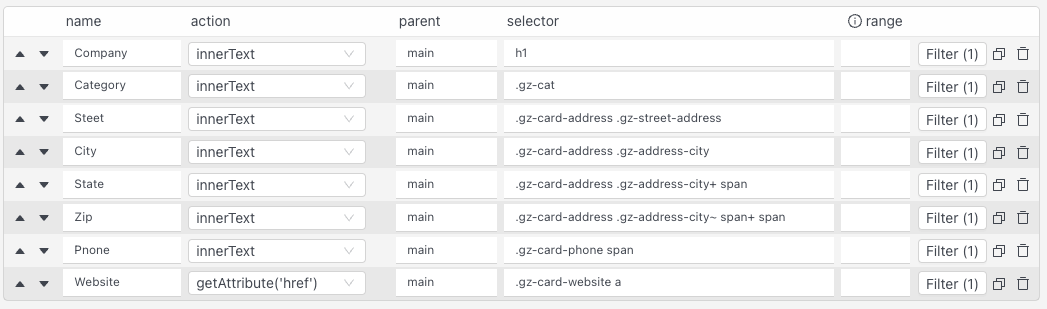
I’m working on a Mac and I set up a dynamic page scraper and named the parent and noticed that it works well except if it doesn’t find a selector element on the page it will not scrape that page. See log entry below showing it ( .gz-card-address .gz-street-address was not found) was not found so it didn’t download this page. For this directory I entered 354 URL’s but only 315 were downloaded. Below is a screen shot of my selectors. Is there a setting that allows to still download these pages even if elements not found?

Can you export the task for me?
I will have a closer look.
Sent to you by email.
Email recv. Investigating.
Thankyou
Dynamic scraper waits for each element to load, and if the page is missing the element it exits early with an error message.
In your project some selectors eg (.gz-social-linkedin) don’t return data for some of the urls you are scraping.
Instead of an error, SCM will wait for the next element in the list to load and continue on instead of throwing an error.
If the data is missing, it just returns a blank column but will save data for anything else it finds.
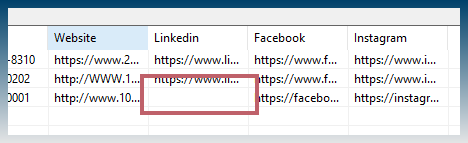
Dynamic scraper assumes all selectors must be on page to continue, however in your project the selectors should be treated as optional.
This will be updated in next version of SCM.
Thank you for investigating and testing. Much Obliged!