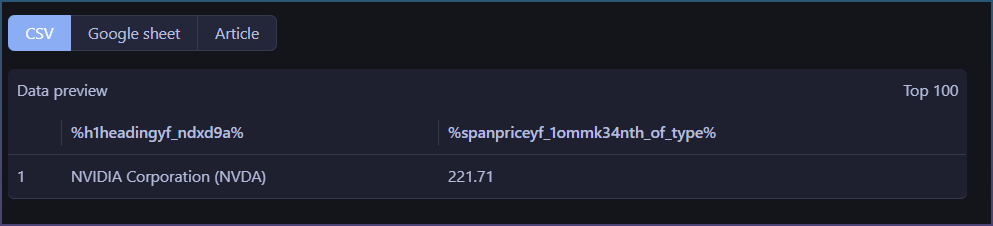
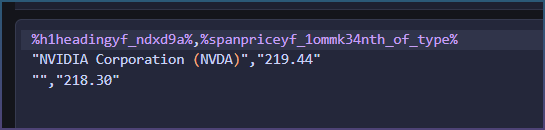
I’m having consistent issues with the Dynamic Page Scraper. It works fine for light or simple HTML pages, but fails on many modern, heavily protected websites.
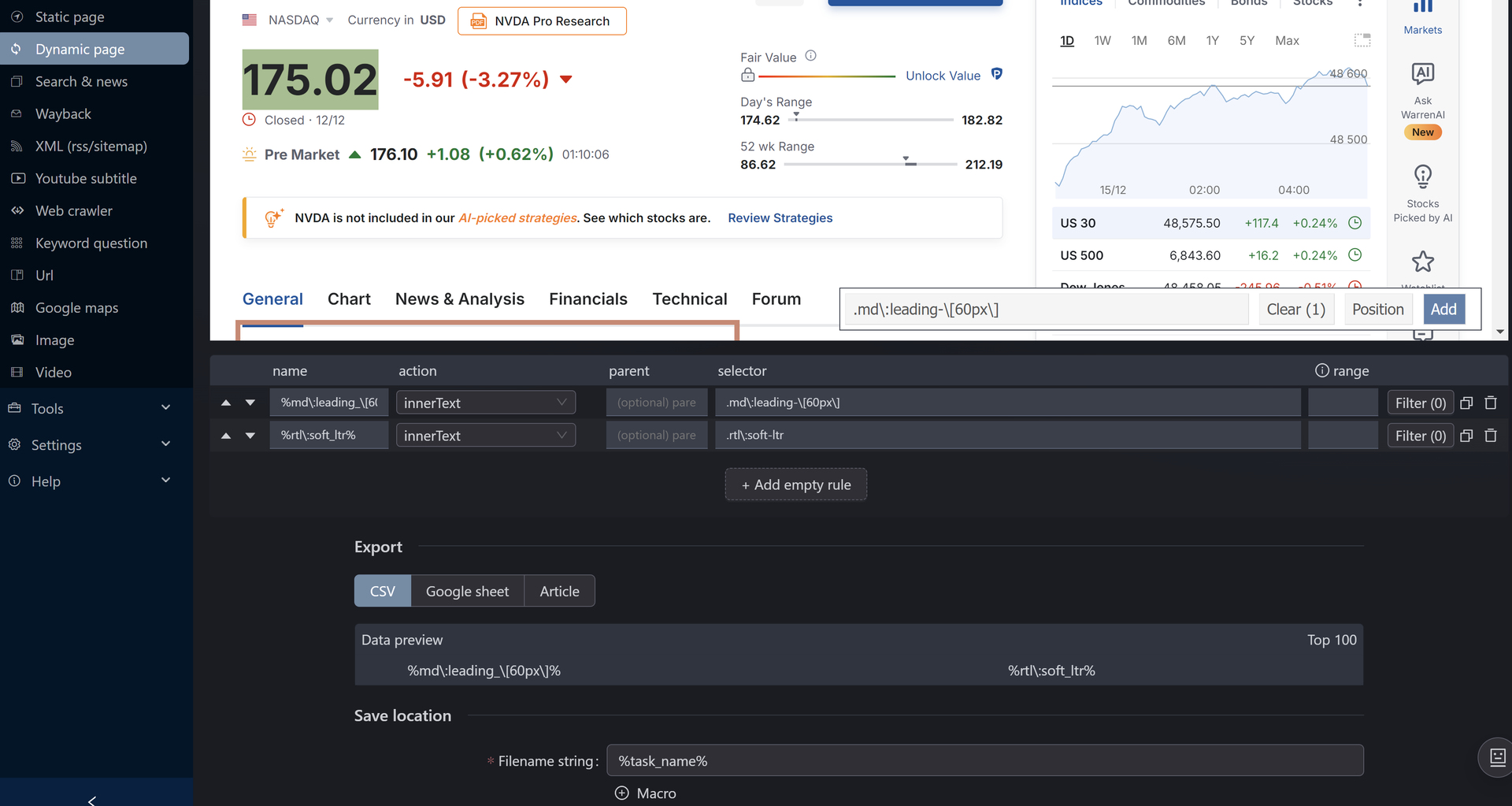
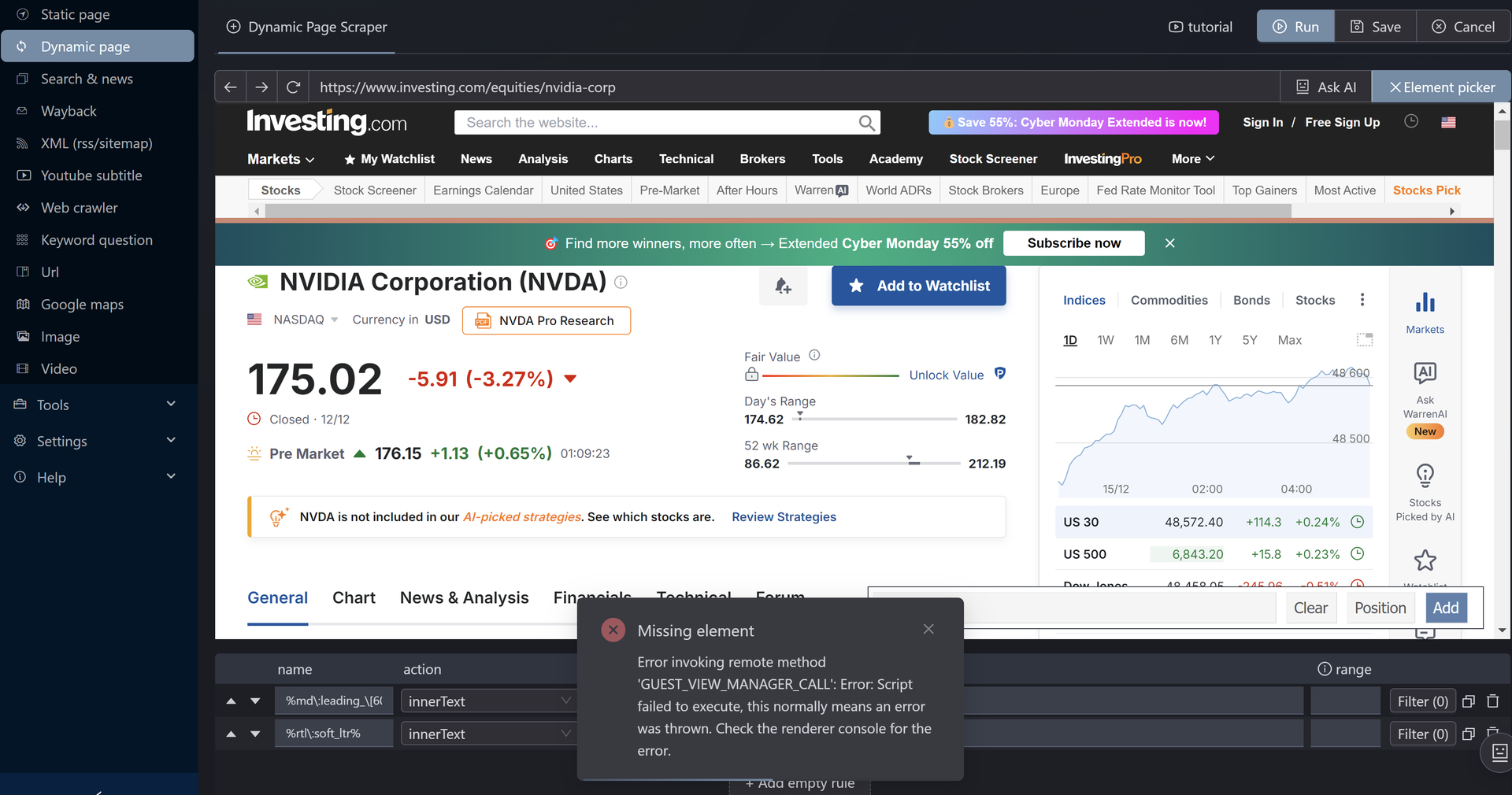
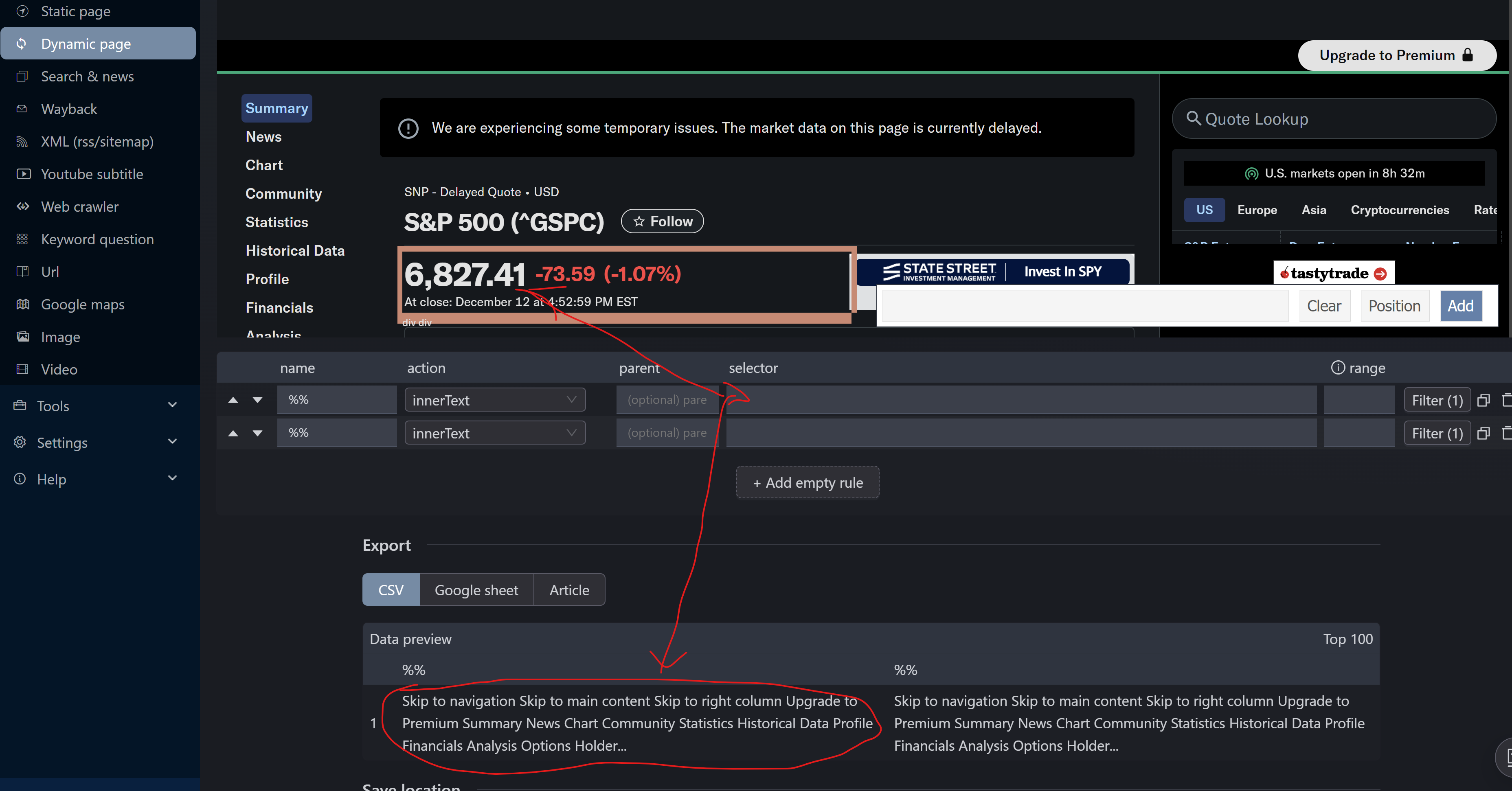
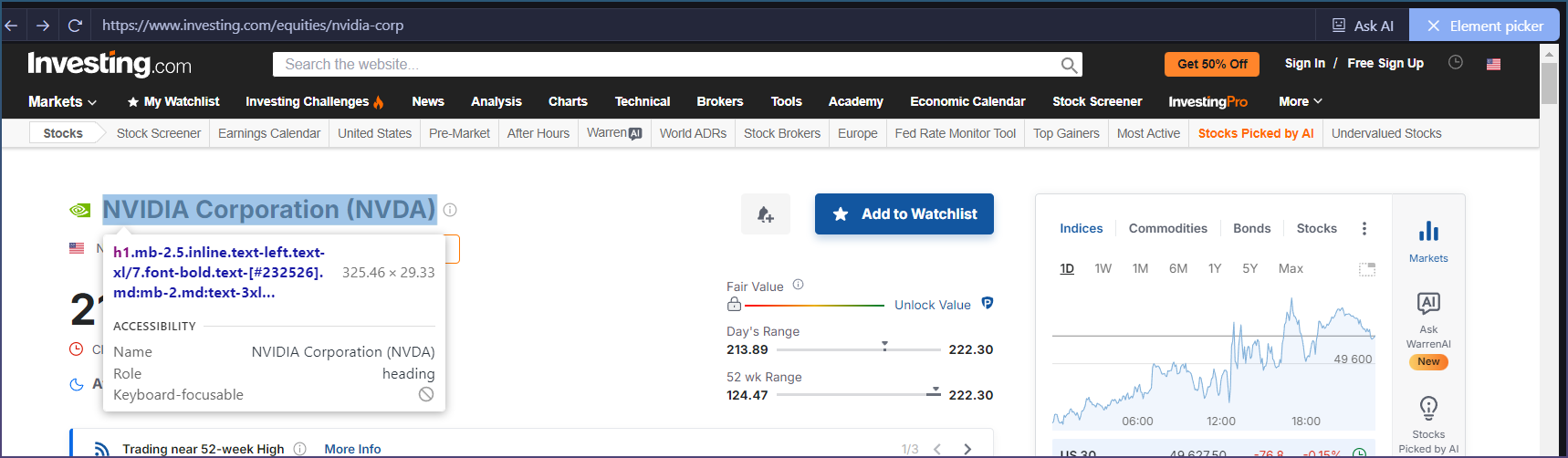
Page loads, but element picker cannot capture any real content
Any selected element results in empty selectors / no actual text
There are more websites I’d like to scrape, but many of them fail in similar ways.
I understand this is challenging because these sites use strong protections (bot detection, automation blocking, JS rendering, etc.). However, it would be very helpful if SCM could support:
Custom User-Agent configuration
Additional browser fingerprint options
Better handling of JS-rendered content
Anti-bot mitigation options
Some scrapers are experimenting with open-source AI browser agents, which may provide ideas or inspiration:
I’m not suggesting copying these tools directly, but they may offer useful concepts for improving dynamic scraping reliability.
It would be good to know how to make the Dynamic Page Scraper work on the websites mentioned above.
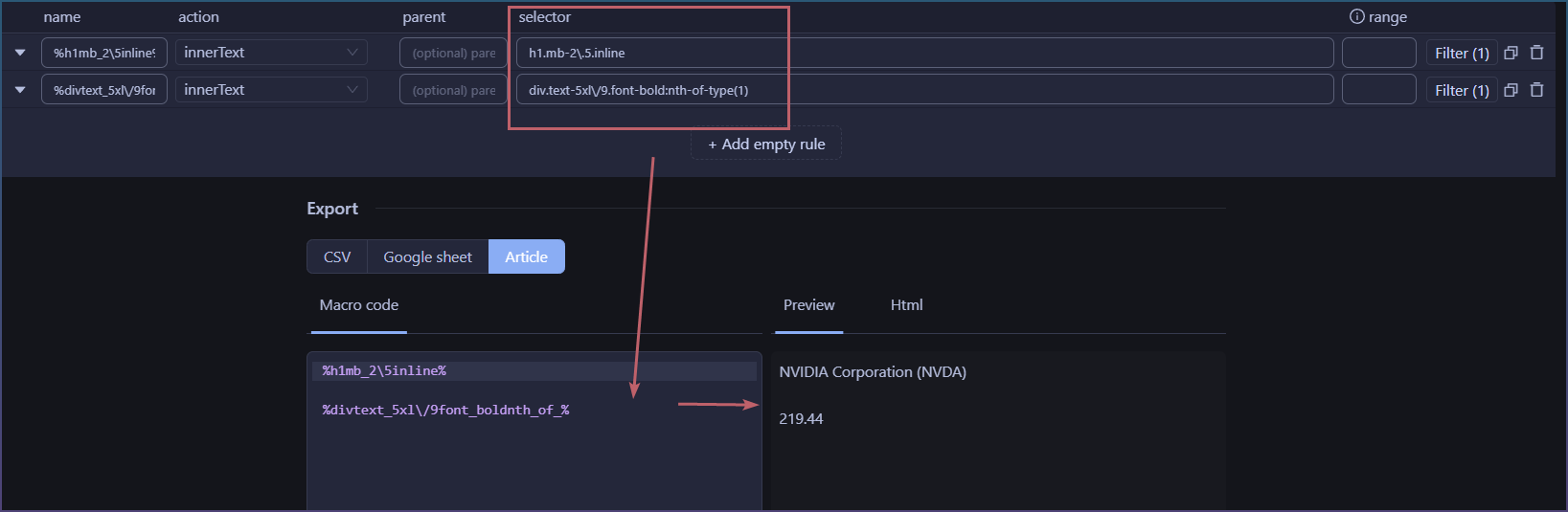
1- right now the selector tools does fail on some complex sites. Ideally we would find a way to use chromes selection tool. FYI the one we use right now is a couple of years old.
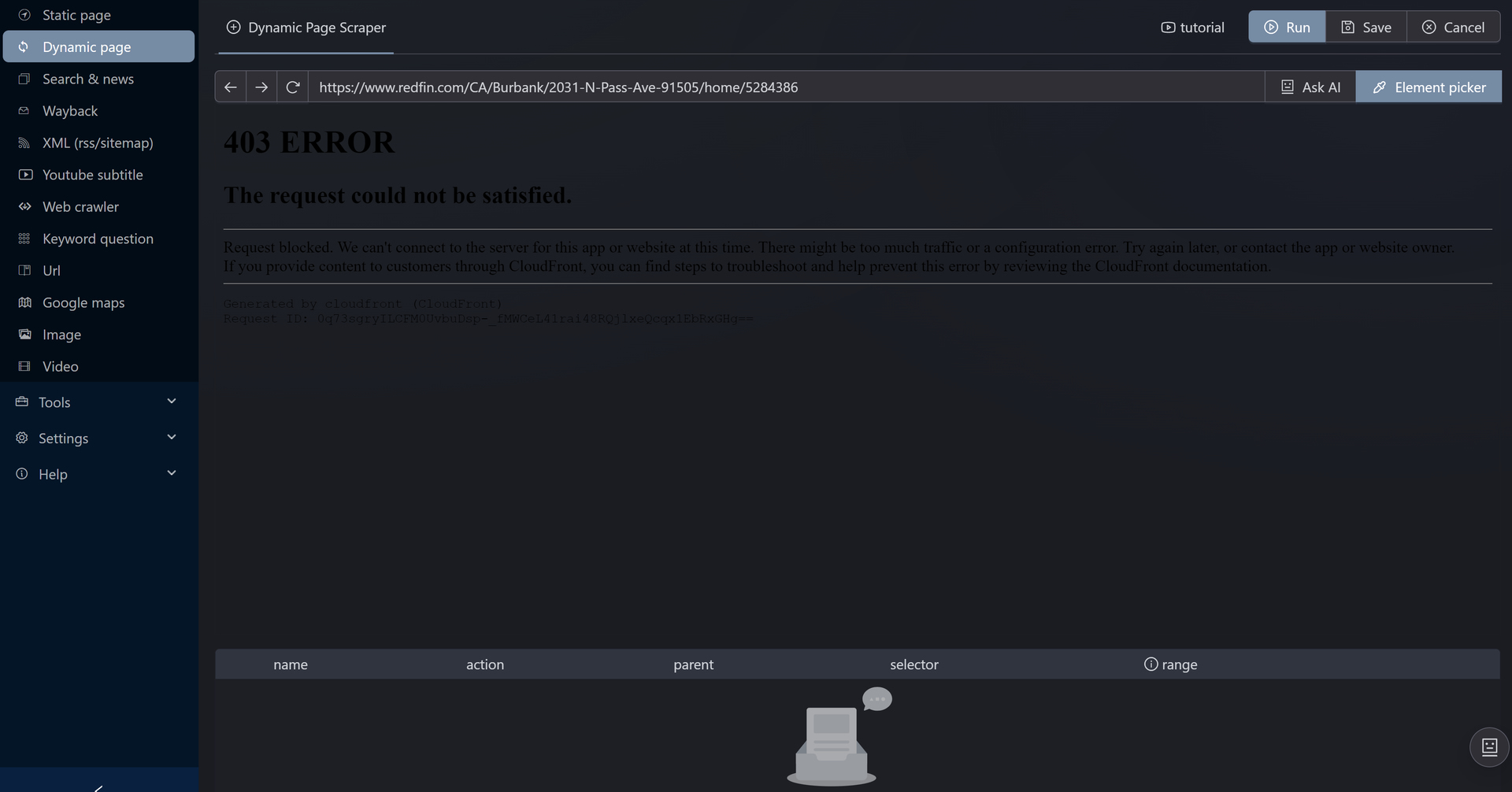
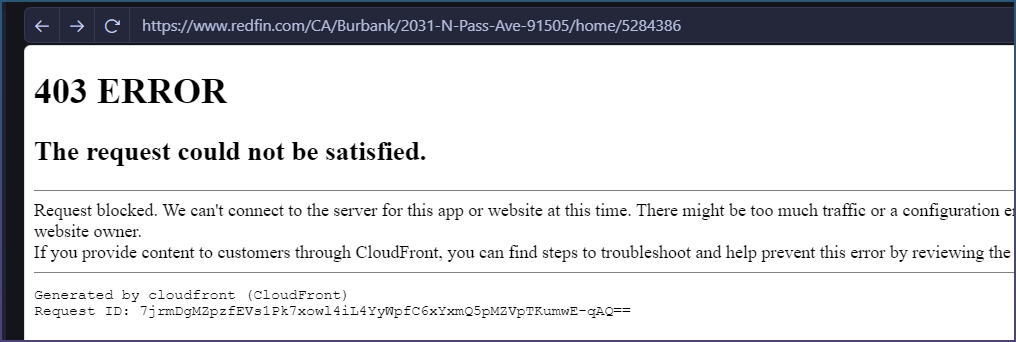
2- as you pointed out some sites have anti scraping code that stops browsers from opening it.
I’m looking at puppeteer for 2 and will need to look for solution’s to 1.
Puppeteer might have some anti scraping mitigation code to reduce fingerprints.
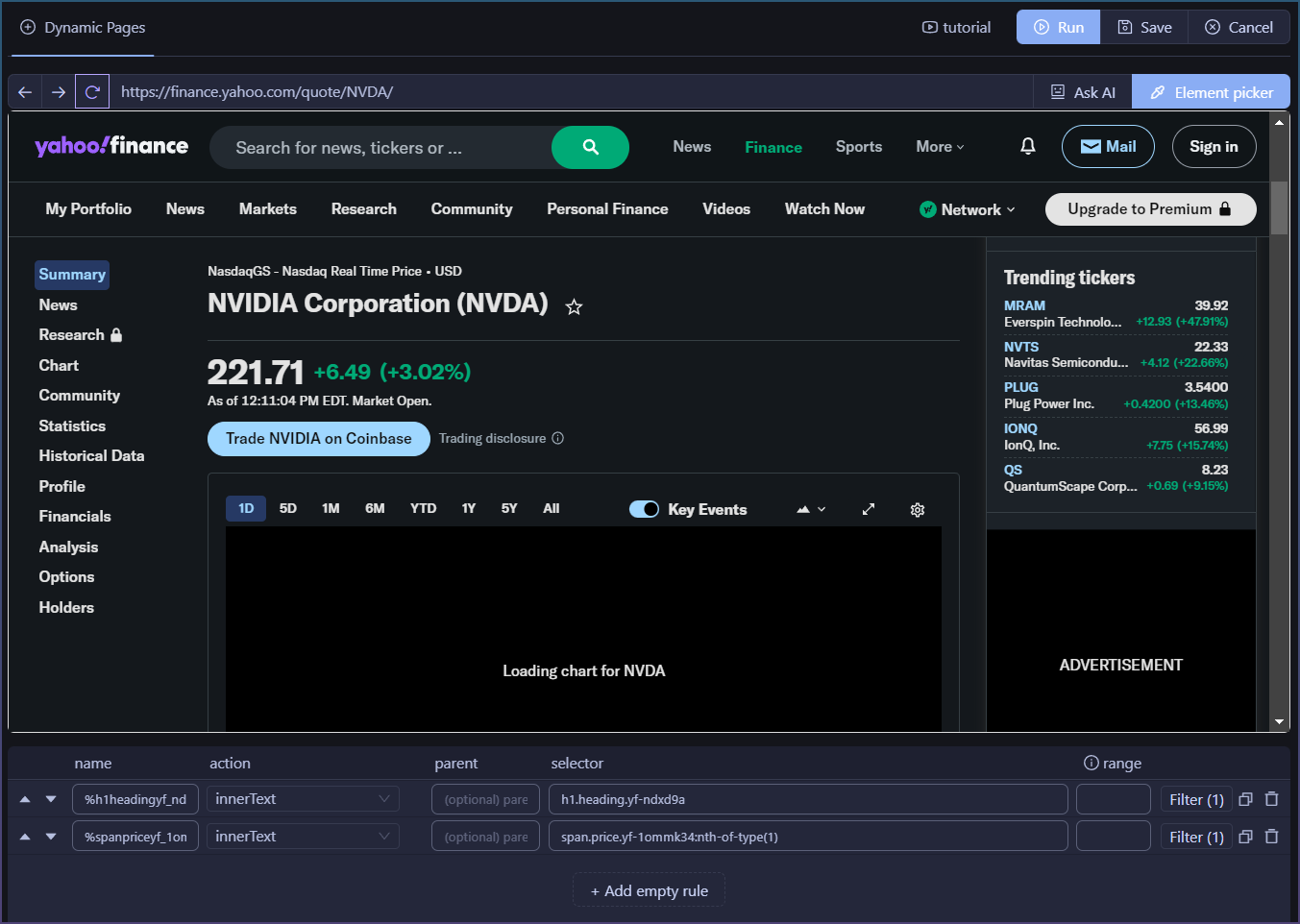
I already have puppeteer working in scm it just requires some user testing.
Thanks, Tim, for testing this and checking all those cases. I really appreciate the detailed breakdown and the improvements already made. 2/3 working on these modern sites is honestly a big step forward compared to before. Looking forward to trying the next update and seeing how the Redfin/Cloudflare handling improves as well.