I am new to SCM.
Is there a way to scrape content within individual URLs?
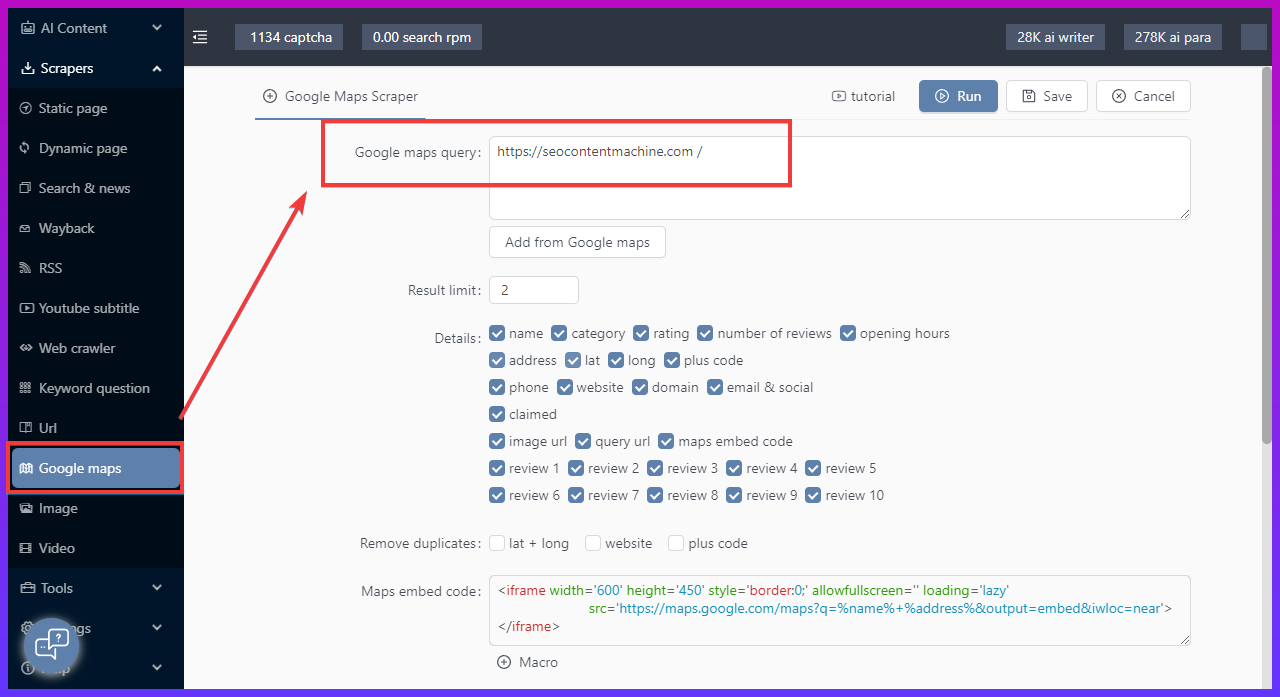
get the URL of each job page on the job list page
extract the content in each URL obtained in 1.
I was able to do 1, but I don’t know how to do 2.
I would also like to know if it is possible to execute JavaScript when doing 2.
Specifically, I want to retrieve the text contain the @ symbol in the page text for 2. If there is a way to do this without using JavaScript, I would like to know that as well.
Sorry for the lack of clarity.
As a result, I want to retrieve the list and the content of the individual items in the list at once.
For example, scraping the content of the Amazon product list page and the individual pages for each of those products at once.
By looping, I mean going from the list page to the individual page, then back to the list page and then to the individual page of the next item.
Is this clear to you?
Unfortunately it will have to be a 2 step process, that exists in 2 tasks.
Gather all individual pages
Process each page individually
The dynamic scraper doesn’t have any flow control or looping
The proposal would be to allow this via webhooks
eg:
Task runs and scrapes a list of urls
Output set to webhook → post json data
The webhook calls SCM api to duplicate or edit existing task and just update the list of target urls using the output
Webhook runs new task
I mention web hooks because after the google sheets integration is finished I want to allow SCM to start integrating with other external tools via web hooks
eg Webhooks's triggers, queries, and actions - IFTTT
Of course webhooks is complicated and like programming, so I will need to find ways to make it as pain less as possible.