When using the Wayback scraper you have the option of selecting specific bits of the html article.
This can be useful when you just want the content on the page, without all the scripts styles etc
By default it selects the entire page ie HTML

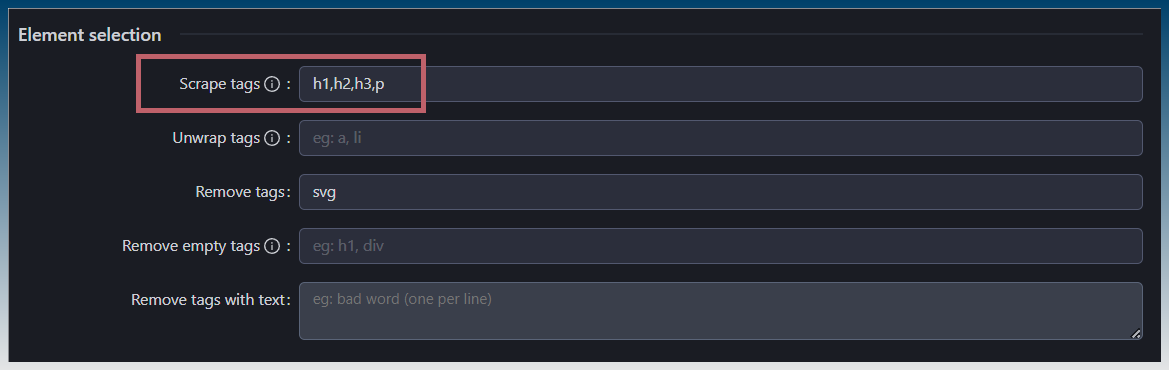
The wayback too will use CSS to select tags.
If you want to only download h1,h2,h3 and p tags.
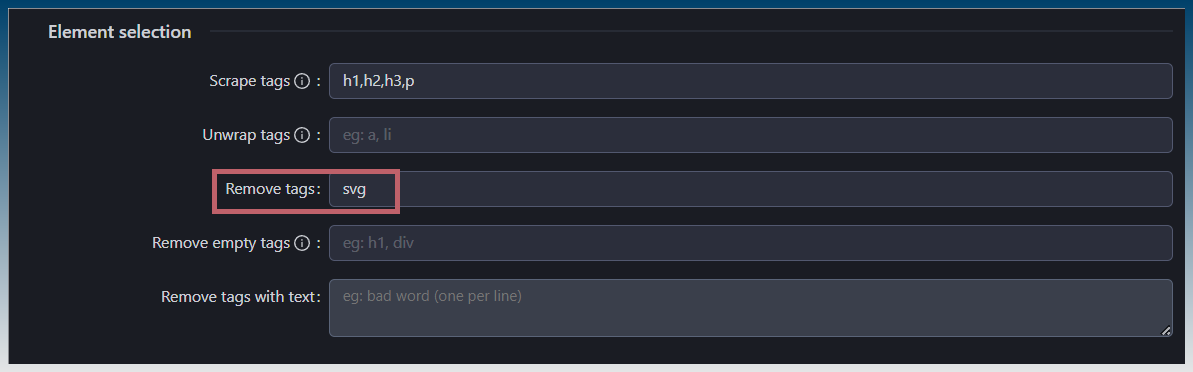
You can also clean up the html by removing tags etc
eg Remove SVG tags from content.