Generating AI articles can be slow if you the article requires multiple prompts to complete.
Eg: AI outline long form templates.
These can generate outlines that require sending multiple prompts to the AI to complete.
A typical example of just 10 prompts…
Most AI models are rate limited, but if you are hosting your own AI models and can run multiple requests in parallel, its possible to increase the speed of article generation when using AI.
How increase the AI article threads limit
Go to settings > task
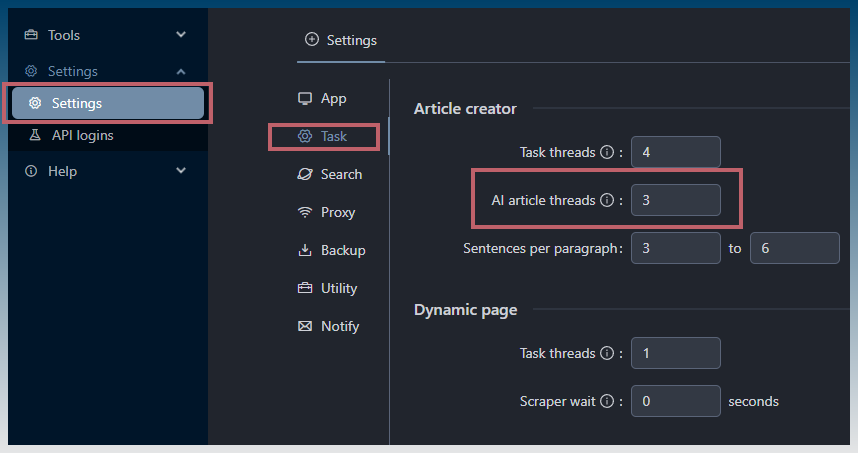
This will bring you to the AI article threads box.
Input a number greater than 1 to allow multiple prompts to be send in parallel to the AI model.
In this example, the default AI article thread value is changed from default 1 to 3.
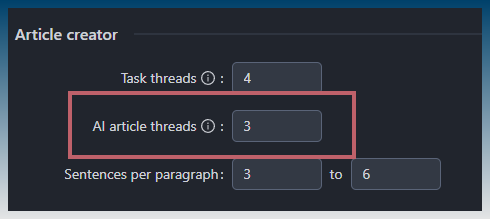
Once changes are made, you can run your Article Creator tasks.
How does the Article creator speed up AI articles?
Once you have increased the thread count, the Article creator will automatically take multiple prompts and split to them up for parallel processing.
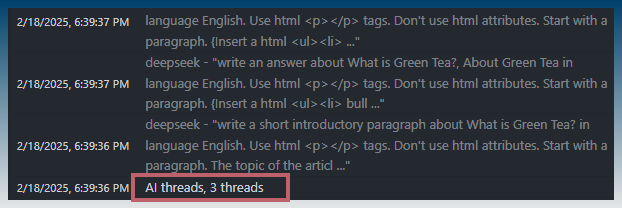
See the task log to verify this.
Article creator requests an AI outline with 10 sections.
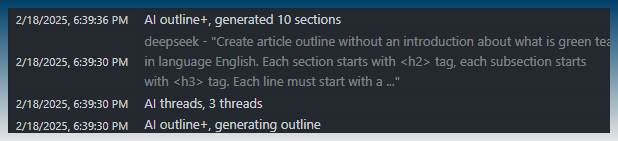
With 10 prompts in queue, the first 3 prompts are sent to the AI model simultaneously.
The task log reports AI threads is set to 3 as confirmation.
You can see 3 prompts are sent at the same time to the AI model.
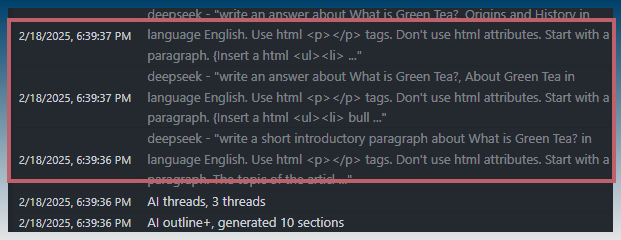
As long as your AI model can process multiple requests in parallel you will get a speed boost to the creation speed of your AI articles.
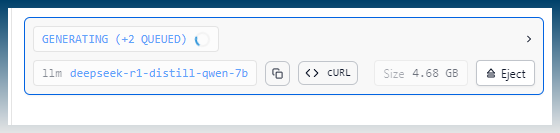
Inside LM studio, further proof of the multiple incoming requests getting queued.
What to watch out for when increasing AI threads
- Most AI models have rate limits, make sure you stay under those by keeping AI threads to a low number.
- If you see errors messages from the AI models about rate limits, you must immediately lower the AI thread count to avoid getting a temporary ban.
- If you are running an AI model locally, there might be no benefit in increasing the thread limit as your hardware might only be big enough to run one instance of the AI model. Multiple requests will be queued at best.
- The default value is 1.