If you want to spider/index a site to discover all the links on it you can use the Web crawler tool.
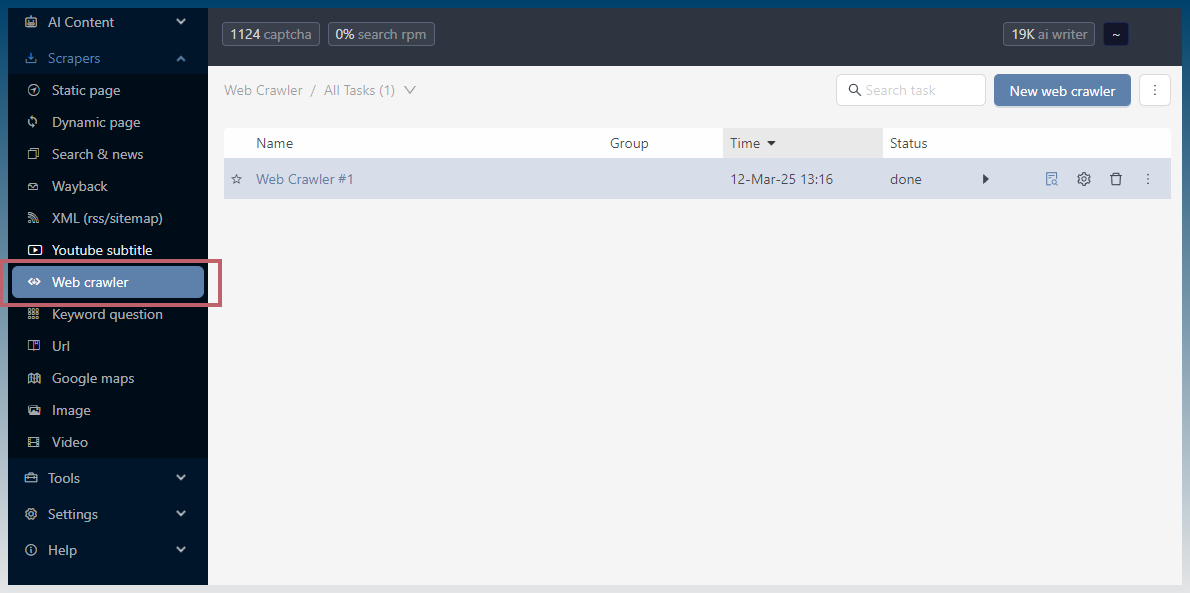
How does the web crawler tool work?
Provide a starting link (or links). The tool will then download each page to discover links.
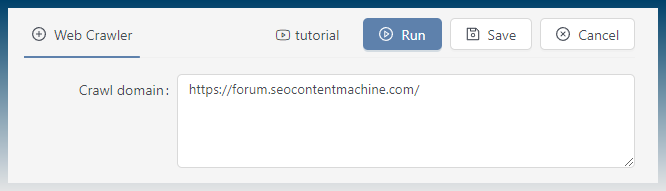
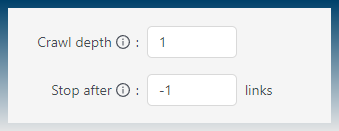
The crawl depth is set to 1, so it will only find links on the pages you give it.
Set it to > 1, ie 2 or 3, to make the crawler follow extra links down.
You can make the crawler exit early after it reaches a set number of links.
Default -1, means it will go forever .
There is some filtering to keep or remove links.
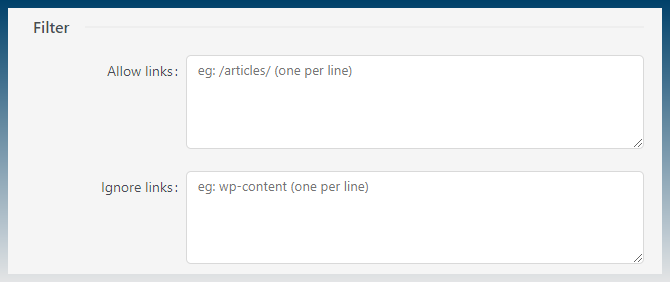
Results are saved to your hard drive.
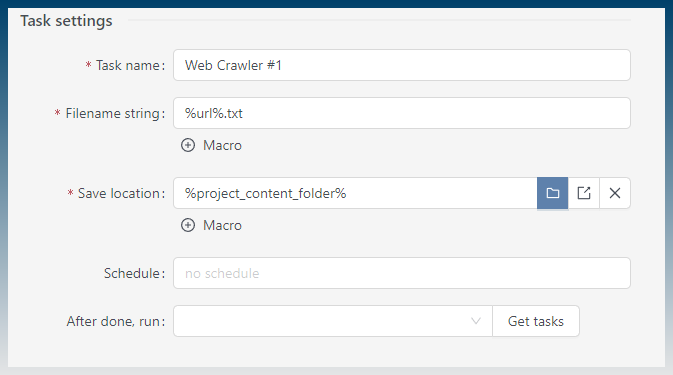
Output will be in 2 files.
- Internal links
- External links

The urls you provide will use the domain to treat it as ‘internal’
How to increase crawling speed
You can increase or decrease the number of threads.
Settings > task
Web crawler threads