Tim
1
FYI
The app is now using a browser to extract page content from serps.
You will see higher mem and CPU usage.
The trade-off is that you should extract more page data as most sites are starting to become JavaScript only.
If this is not the case and higher mem and cpu usage isn’t leading to meaningful returns on content please let me know.
The old method was to use simple string download.
I am investigating ways to optimize.
I have already made significant optimizations to job table.
Tim
2
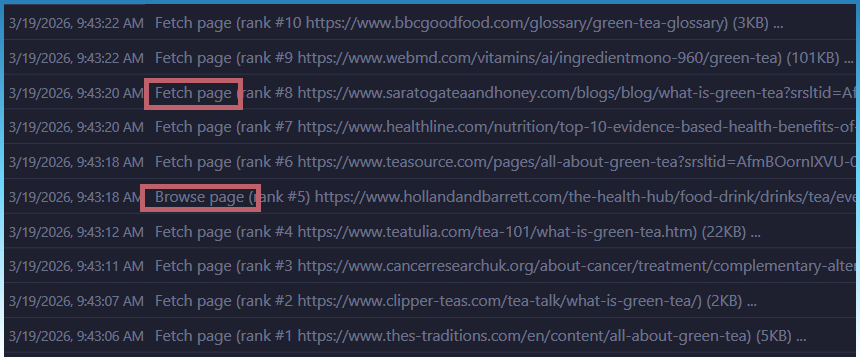
Page extractor will try simple fetch first.
If it can’t find content it will open a browser window.
Fetch page or Browse page in log to see what was done.
I also fixed the fetch page.
It now access page more like a browser, so its more likely to work first try.
If it needs to open a browser, it does so with minimal assets.
Ie tries not to download images, stylesheets, media etc
This should lower mem usage and you get best of both worlds.