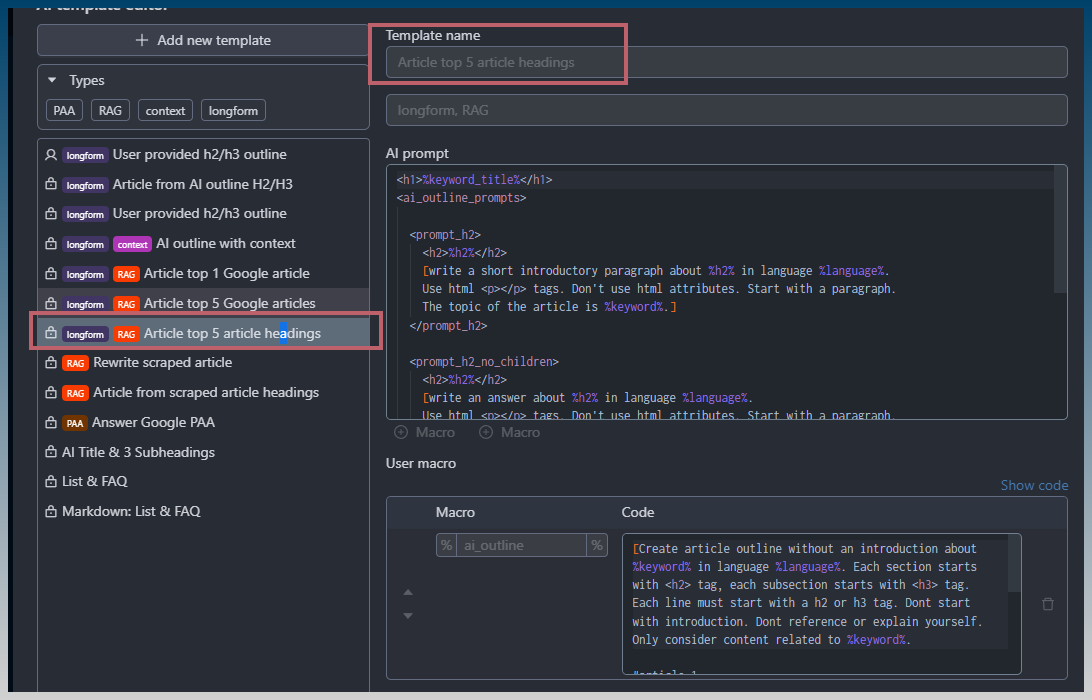
I’m using Groq AI free to generate article with the template longform RAG Article top 5 Google articles.
But it says the message " {“status”:413,“data”:{“error”:{“message”:“Request too large for model llama3-70b-8192 in organization org_01jg9fs34zfe0vq0dm5aez9n0f on tokens per minute (TPM): Limit 6000, Requested 10695, please reduce your message size and try again. Visit GroqCloud for more information.”,“type”:“tokens”,“code”:“rate_limit_exceeded”}}} retry 3/3 in 32s"
Is there anyway we can fix this? I currently cannot generate anything due to the exceeded token per minute issue.
How do you think about the model “llama-3.1-8b-instant” ? I see that it has up to 20,000 token per minute so I use this one. But I’m not sure if it’s as good as the model llama3-70b-8192.